Kubernetes
k8s介绍
- Kubernetes舵手。8替代K和s中的8个字母,Google开源基于Go
- Kubernetes和Docker两个互补。Docker侧重于容器化应用,Kubernetes专注于容器编排。Docker开发应用、打包、测试和交付,Kubernetes在生产、测试环境中编排应用的运行
- k8s类似云上的操作系统对资源进行抽象,并对多种云原生微服务应用进行调度
k8s架构
Kubernetes集群由主节点(master)与工作节点(node)组成。这些节点都是Linux主机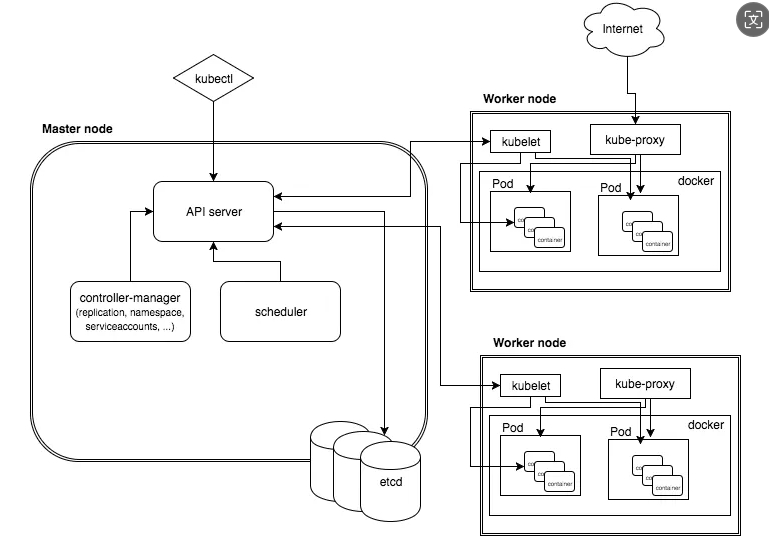
- 主节点(master控制平面):组成集群的控制平面的系统服务的集合。3-5个副本保证高可用
- API Server(API服务):负责所有组件(系统内置组件以及外部用户组件)之间的通信。对外通过HTTPS的方式提供了RESTful风格的API接口。访问API Server的全部请求都必须经过授权与认证
- Controller Manager:管理和执行各种控制器(如 ReplicaSet、Deployment、StatefulSet等)。实现了全部的后台控制循环,完成对集群的监控并对事件作出响应
- Controller(Deployment、DaemonSet以及StatefulSet):每个controller都在后台启动了独立的监控循环功能,负责监控API Server的变更。每个控制循环都只关心与自己相关的逻辑。保证集群的当前状态(current state)与期望状态(desired state)相匹配。每个控制循环的基础逻辑如下。1获取期望状态2观察当前状态3判断两者间的差异。4变更当前状态来消除差异点
- Scheduler:通过监听API Server来启动新的工作任务,并将其分配到适合的且处于正常运行状态的节点中。调度器过滤掉不能运行指定任务的工作节点并排序。选择分数最高的节点来运行指定的任务。然后进行多种前置校验包括:节点是否仍然存在、是否有affinity或者anti-affinity规则、任务所依赖的端口在当前工作节点是否可以访问、工作节点是否有足够的资源等。过滤不满足任务执行条件的工作节点,最后根据规则计算得分并排序,包括:工作节点上是否已经包含任务所需的镜像、剩余资源是否满足任务执行条件,正在执行多少任务。得分最高的工作节点执行任务。如果调度器没找到合适的工作节点,那么任务会被标记为暂停状态
- ETCD:在整个控制层中,只有集群存储是有状态(stateful)的部分,持久化地存储了整个集群的配置与状态。底层用分布式数据库etcd。运行3~5个副本保证高可用。etcd认为一致性比可用性更重要。在出现脑裂时会停止为集群提供更新能力来保证存储数据的一致性。etcd不可用时应用仍然可以在集群性持续运行,只不过无法更新任何内容而已。etcd用RAFT一致性算法
- 工作节点:集群的工作者。负责1. 监听API Server分派的新任务。2. 执行新分派的任务。3. 通过API Server向控制平面回复任务执行的结果。
- Kubelet:工作节点核心,每个工作节点上都有部署。负责将当前工作节点注册到集群当中,集群的资源池就会获取到当前工作节点的CPU、内存以及存储信息,并将工作节点加入当前资源池。负责监听API Server新分配的任务并执行,维护与控制平面之间的一个通信频道,准备将执行结果反馈回去。如果Kuberlet无法运行指定任务,就会将这个信息反馈给控制平面,并由控制平面决定接下来要采取什么措施
- 容器运行时 (Docker、Containerd、...):Kubelet需要容器运行时(container runtime)来执行依赖容器才能执行的任务,例如拉取镜像并启动或停止容器。k8s通过运⾏时接⼝(CRI)的模块支持不同的容器运行时
- Kube-proxy:运行在每个工作节点,负责本地集群网络。例如保证每个工作节点都可以获取到唯一的IP地址,并且实现了本地IPTABLE以及IPVS来保障Pod间的网络路由与负载均衡
POD、Pause容器、yaml定义pod(了解),POD生命周期与重启、拉取策略,利用探针实现POD健康检查,对外暴露,Pod调度与节点亲和性,污点(Taint)与容忍度(Toleration).LimitRange与ResourceQuota
- Docker中调度的原子单位是容器;K8s中最小调度的原子单位是Pod。每个Pod中运行一个或一组容器,称为多容器Pod(multi-container Pod)
- 同一个Pod中运行多个容器会共享相同的Pod环境。包括了IPC命名空间,内存,磁盘、网络以及其他资源,如IP地址。容器之间可以用localhost接口通信。
- 多容器Pod适用于存在强绑定关系的多个容器,比如需要共享内存与存储。如果容器间并不存在如此紧密的关系,最好将容器封装到不同的Pod,通过网络以松耦合的方式来运行。在任务级别实现容器间的隔离,降低相互之间的影响。但会导致大量的未加密的网络流量产生。
- Pause容器:infrastucture container(infra)基础容器,
- 每个Pod运行一个Pause的容器,其他容器(业务容器)都从pause容器中fork出来,共享Pause容器的网络栈和Volume挂载卷。因此他们之间通信和数据交换更为高效
- Pause容器为每个业务容器提供以下功能:
PID命名空间:Pod中的不同应用程序可以看到其他应用程序的进程ID。
网络命名空间:Pod中的多个容器能够访问同一个IP和端口范围。
IPC命名空间:Pod中的多个容器能够使用SystemV IPC或POSIX消息队列进行通信。
UTS命名空间:Pod中的多个容器共享一个主机名
Volumes(共享存储卷):Pod中的各个容器可以访问Pod级别的Volumes - 扩容或缩容应用时通过添加或删除Pod来实现。不要向已经存在的Pod中增加容器来扩容
- Pod的部署是一个原子操作。只有当Pod中的所有容器都启动成功且处于运行状态时,Pod提供的服务才是可用的,一个Pod(即使包含多容器)只会被唯一的工作节点调度
- 如果Pod出现预期外的销毁时会启动新Pod来取代有问题的Pod。有全新的ID与IP地址。不要在设计程序的时依赖特定的Pod
yaml定义pod
# 编写yaml
mkdir /etc/k8s
cat > /etc/k8s/nginx-pod.yaml <<-'EOF'
# API版本号,固定写v1即可
apiVersion: v1
# 创建对象类型
kind: Pod
# 元数据,描述pod的辅助信息
metadata:
# pod名称
name: pod-nginx
# 设置容器、镜像等关键选项
spec:
# 重启策略
restartPolicy: Never
containers:
# 容器名称
- name: container-nginx
# 镜像名称
image: nginx:1.20.2-alpine
# 镜像拉取策略
imagePullPolicy: IfNotPresent
# 容器内部暴露的端口号,即expose
ports:
# nginx容器默认对外暴露80端口
- containerPort: 80
# 配置存活探针,每五秒钟执⾏⼀次探测容器80端⼝是否准备就绪
# ⽽第⼀次探测执⾏前先等待10秒,留出必要的初始化时间
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
periodSeconds: 5
readinessProbe:
httpGet:
path: /abcde
port: 80
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
EOF
kubectl apply -f /etc/k8s/nginx-pod.yaml
#移除
kubectl delete -f /etc/k8s/nginx-pod.yaml
# 查看已部署的Nginx节点
kubectl get pods -A -o wide
# 查看指定pod明细
kubectl describe pod pod-nginx
# 查看输出的日志
kubectl logs -f pod-nginx
# 查看运行时命令
crictl ps
Pod生命周期五个阶段
- 运行中(Running):Pod已经绑定到了一个节点上,所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
- 等待中(Pending): 创建Pod请求已被接受,但有一个或者多个容器镜像尚未创建
- 正常终止(Succeeded):pod中的所有的容器已经正常退出,并且永远不会自动重启这些容器,一般在部署job时出现
- 异常停止(Failed):Pod中的所有容器都已终止了,并且至少有一个容器是因为失败终止。容器以非0状态退出或者被系统终止
- 未知状态(PodUnkonwn):出于某种原因,无法获得Pod的状态,通常是与Pod主机通信出错
Pod详细状态
- CrashLoopBackOff:容器退出,正在重启,建议增加内存、CPU等资源
- InvalidImageName: 无法解析镜像名称
- ImageInspectError: 无法校验镜像
- ErrImageNeverPull: 策略禁止拉取镜像
- ImagePullBackOff: 正在重试拉取,建议更换镜像仓库
- RegistryUnavailable: 连接不到镜像中心
- ErrImagePull: 通用的拉取镜像出错
- CreateContainerConfigError: 不能创建kubelet使用的容器配置
- CreateContainerError: 创建容器失败
- m.internalLifecycle.PreStartContainer 执行hook报错
- RunContainerError: 启动容器失败
- PostStartHookError: 执行hook报错
- ContainersNotInitialized: 容器没有初始化完毕
- ContainersNotReady: 容器没有准备完毕
- ContainerCreating:容器创建中,长时间卡死要decribe与logs查看日志分析内容
- PodInitializing:pod初始化中
- DockerDaemonNotReady:docker还没有完全启动
- NetworkPluginNotReady:网络插件还没有完全启动
POD重启策略spec.restartPolicy:适用于pod中的所有首次需要重启的容器,随后再次需要重启将延迟一段时间后进行,时长为10,20,40,80,160,300s
- Always(默认):容器失效时,自动重启该容器
- OnFailure:容器停止运行且退出码不为0时重启
- Never:任何状态都不重启容器
POD镜像拉取策略spec.containers[i].imagePullPolicy - IfNotPresent(默认),镜像不存在时拉取(面对稳定版本)
- Always:每次创建Pod都重新拉取镜像(面对不断变更版本)
- Never:永远不会拉取镜像
Pod实现健康检查三种探针类型spec.containers[i].StartupProbe:
- StartupProbe:用于判断容器内应用程序是否已经启动。会先禁止其他的探测直到成功为止,成功后将不再进行探测。适用于容器启动时间长的场景
- LivenessProbe(存活探针):用于探测容器是否运行,探测失败会根据配置的重启策略进行处理。没有配置则默认success。
- ReadinessProbe(就绪探针):用于探测容器内的程序是否健康,返回值为success代表容器完成启动,并且程序是可以接受流量的状态
三者区别 - 存活探针用于确定重启容器时机。例如探测到死锁。提高应用的可用性,即使其中存在缺陷
- 就绪探针可以确定容器准备好接受请求流量时机,当所有容器都就绪时,才能认为该Pod就绪。用于控制Pod作为Service的后端。Pod尚未就绪会被从Service的负载均衡器中剔除
Pod探针的四种检测方式spec.containers[i].StartupProbe.httpGet:
- exec:在容器内执行命令返回值为0,则认为容器健康。
- tcpSocket:通过TCP连接检查容器内的端口是否连通,连通则容器健康
- httpGet(常用):通过程序暴露的API地址检查程序是否正常,如果状态码为200~400,则容器健康
- grpc:用gRPC执行远程过程调用。如果响应的状态是"SERVING",则认为诊断成功。
探测结果 - Success(成功):容器通过了诊断。
- Failure(失败):容器未通过诊断。
- Unknown(未知):诊断失败,因此不会采取任何行动。
配置范本: - 容器启动5秒后发送第一个存活探针。尝试连接nginx容器的80端口。如果探测成功,Pod会被标记为就绪状态,每隔10秒运行一次探测
- 就绪探针periodSeconds字段指定每隔3秒执行一次存活探测
- initialDelaySeconds 字段在执行第一次探测前等待3秒。向容器内运行的服务(服务监听8080端口)发送HTTP GET请求来探测。如果服务器上/healthz路径下的处理程序返回成功代码,则认为容器是健康存活的。如果返回失败代码,则会杀死容器并重启。返回200-400的任何代码都表示成功,其它表示失败
对外暴露端口
| 方法 | 优点 | 缺点 |
|---|---|---|
| NodePort | 简单、适合测试环境 | 端口范围受限,暴露到所有节点 |
| LoadBalancer | 云环境原生支持,外部访问简单 | 仅支持云环境,可能有额外成本 |
| Ingress | 强大的路由和域名支持,生产环境 | 要额外部署 Ingress Controller |
| 直接暴露(HostPort) | 配置简单 | 不推荐,破坏抽象,难以扩展和管理 |
调度是指将Pod放置到合适的节点上,以便对应节点上运⾏Pod
调度器通过K8s的监测Watch机制来发现集群中新创建且尚未被调度到节点上的Pod。调度器会将发现的每个未调度的Pod调度到合适的节点上运⾏
kube-scheduler是默认调度器,在设计上允许你⾃⼰编写⼀个调度组件并替换原有的kube-scheduler
Kube-scheduler选择⼀个最佳节点来运⾏新建或尚未调度(unscheduled)的Pod。由于Pod中的容器和Pod本身可能有不同的要求,调度程序会过滤掉任何不满⾜Pod特定调度需求的节点。API允许在创建Pod时指定节点
满⾜Pod调度请求的所有节点称之为可调度节点。如果没有节点能满⾜Pod的资源请求,那么Pod将⼀直停留在未调度状态直到调度器找到合适节点
调度器先找到⼀个Pod的所有可调度节点,然后对可调度节点打分,选出其中得分最⾼的节点来运⾏Pod。调度器将调度决定通知给kube-apiserver,这个过程叫做绑定
做调度决定时要考虑的因素:单独和整体的资源请求、硬件/软件/策略限制、亲和以及反亲和要求、数据局部性、负载间的⼲扰等等。
kube-scheduler给Pod做调度选择时包含两个步骤
过滤阶段:将所有满⾜Pod调度需求的节点选出来。例如PodFitsResources过滤函数会检查候选节点的可⽤资源能否满⾜Pod的资源请求。过滤后得出所有可调度节点的节点列表;通常包含不⽌⼀个节点。如果这个列表是空的,代表Pod不可调度
打分阶段:为Pod从所有可调度节点中选取最合适的节点。根据打分规则给每⼀个可调度节点打分。最后将Pod调度到得分最⾼的节点上。如果存在多个得分最⾼的节点,则从中随机选取⼀个
过滤和打分配置
调度策略:配置过滤所⽤的断⾔(Predicates)和打分优先级(Priorities)
调度配置:配置实现不同调度阶段的插件,包括QueueSort、Filter、Score、Bind、Reserve、Permit等
Affinity亲和性:当满⾜了某些条件就把Pod调度到集群上。Anti-Affinity相反,~不把Pod调度到集群上.
Taint污点和Toleration容忍,Taint提供Node的标记,但标记不是Label,当设置好Taint后,满⾜Toleration的Pod将可以部署到该Node上。
Node Selector和Label可以实现精确筛选
# 新增有nodeSelector的Pod
mkdir/etc/k8s
cd/etc/k8s
cat> pod-nginx.yaml <<-'EOF'
apiVersion: v1
kind: Pod
metadata:
name: pod-nginx
spec:
containers:
- name: container-nginx
image: nginx:1.20.2-alpine
ports:
- containerPort: 80
nodeSelector:
disk: ssd # 放置到具有 "disk=ssd" 标签的节点上
EOF
kubectl delete -f pod-nginx.yaml
kubectl apply -f pod-nginx.yaml
# 检查集群的Node状态,包含Labels,处于Pending状态,describe也提示⽆法匹配
kubectl get po
NAME READY STATUS RESTARTS AGE
pod-nginx 0/1 Pending 0 24s
kubectl get no --show-labels
kubectl describe po pod-nginx
Warning FailedScheduling 6s default-scheduler 0/1 nodes are available: 1 node(s) didn't match Pod's node affinity/selector. preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling.
# 新增disk=ssd的Label并检查
kubectl label nodes node1 disk=ssd
kubectl get no --show-labels
# ⼜开始跑了,如果再度检查describe的讯息中的Event会发现:
kubectl describe po pod-nginx
# 要删除标签,需要的key后⾯增加减号即可
kubectl label node node1 disk-
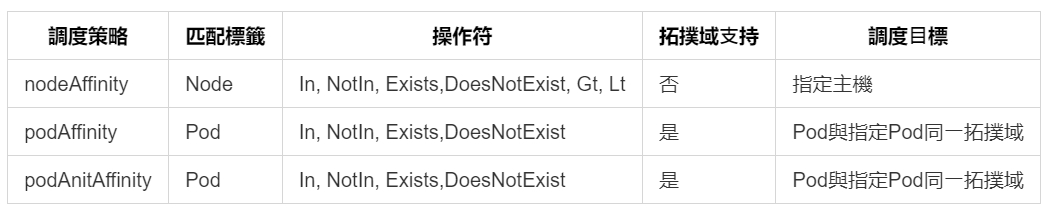
Affinity分类
1、Node Affinity:和Node Selector不同的是,它会有更多细緻的操作,NodeSelector看成是简易版的NodeAffinity,
两种策略:
preferredDuringSchedulingIgnoredDuringExecution:软策略,可以不满⾜
requiredDuringSchedulingIgnoredDuringExecution:硬策略,⼀定要满⾜
matchExpressions的key
kubernetes.io/hostname
failure-domain.beta.kubernetes.io/zone
failure-domain.beta.kubernetes.io/region
beta.kubernetes.io/instance-type
beta.kubernetes.io/os
beta.kubernetes.io/arch
operator操作符
In:Label的值在某个列表中
NotIn:Label的值不在某个列表中
Gt:Label的值⼤于某个值
Lt:Label的值⼩于某个值
Exists:某个Label存在
DoesNotExist:某个Label不存在
weight权重1~100,越⾼越优先考虑
# 新的Pod不允许部署在Node0上,在剩余节点中优先部署在disk=ssd的Node上
mkdir /etc/k8s
cd /etc/k8s
cat > pod-nginx.yaml <<-'EOF'
apiVersion: v1
kind: Pod
metadata:
name: pod-nginx
spec:
containers:
- name: container-nginx
image: nginx:1.20.2-alpine
ports:
- containerPort: 80
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn
values:
- node0
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disk
operator: In
values:
- ssd
EOF
kubectl delete -f pod-nginx.yaml
kubectl apply -f pod-nginx.yaml
kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMI
pod-nginx 1/1 Running 0 6s 10.244.0.147 minikube <none> <none>
2、Pod Affinity
也有两种类型:
requiredDuringSchedulingIgnoredDuringExecution
preferredDuringSchedulingIgnoredDuringExecution
Pod间亲和性,⽤Pod规约中的.affinity.podAffinity字段
Pod间反亲和性,⽤Pod规约中的.affinity.podAntiAffinity字段
亲和性规则:仅当节点和⾄少⼀个已运⾏且有security=S1的标签的Pod处于同⼀区域时,才可以将该Pod调度到节点上。更确切说,必须将Pod调度到具有topology.kubernetes.io/zone=V标签的节点上,并且集群中⾄少有⼀个位于该可⽤区的节点上运⾏着带有security=S1标签的Pod。
反亲和性规则:如果节点处于Pod所在的同⼀可⽤区且⾄少⼀个Pod具有security=S2标签,则该Pod不应被调度到该节点上。更确切说,如果同⼀可⽤区中存在其他运⾏着带有security=S2标签的Pod节点,并且节点具有标签topology.kubernetes.io/zone=R,Pod不能被调度到该节点上
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S1
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: topology.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: registry.k8s.io/pause:2.0
污点(Taint)与容忍度(Toleration)
节点亲和性是Pod的属性,使Pod被吸引到特定的节点(出于偏好或硬性要求)
污点(Taint)相反,使节点排斥特定的Pod
容忍度(Toleration)⽤于Pod。允许调度器调度带有对应污点的Pod。但并不保证调度
污点和容忍度配合⽤来避免Pod被分配到不合适的节点上
Taint的策略:
NoSchedule:POD不会被调度到标记为taints节点。
PreferNoSchedule:NoSchedule的软策略版本。
NoExecute:⼀旦Taint⽣效,如该节点内正在运⾏的POD没有对应Tolerate设置会被逐出
# 设置污点
kubectl taint nodes node0 app=nginx:NoSchedule
# 去除污点
kubectl taint nodes node0 app=nginx:NoSchedule-
cat > deploy-nginx.yaml <<-'EOF'
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.20.2-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
EOF
kubectl delete -f deploy-nginx.yaml
kubectl apply -f deploy-nginx.yaml
# 没有任何⼀台服务器可以部署,因为所有node认为app=nginx是污点,不予部署
kubectl get po
nginx 0/1 Pending 0 2m9s
# 设置容忍度,允许app=nginx部署在app=nginx:NoSchedule的节点上
cat > deploy-nginx.yaml <<-'EOF'
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.20.2-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
tolerations:
- key: "app"
operator: "Equal"
value: "nginx"
effect: "NoSchedule"
EOF
kubectl delete -f deploy-nginx.yaml
kubectl apply -f deploy-nginx.yaml
# 有了
kubectl get po -o wide
nginx 1/1 Running 0 2m9s
LimitRange与ResourceQuota
LimitRange(限制范围)
默认情况下,K8s集群上的容器运⾏使⽤的计算资源没有限制
使⽤资源配额可以在⼀个指定的命名空间内限制集群资源的使⽤与创建
⼀个Pod最多能够使⽤命名空间的资源配额所定义的CPU和内存⽤量
LimitRange是限制命名空间内每个适⽤的对象类别(例如Pod或PersistentVolumeClaim)指定的资源分配量(限制和请求)的策略对象
LimitRange对象能够限制在⼀个命名空间中实施:
对每个Pod或Container最⼩和最⼤的资源使⽤量的限制。
对每个PersistentVolumeClaim能申请的最⼩和最⼤的存储空间⼤⼩的限制。
对⼀种资源的申请值和限制值的⽐值的控制。
对计算资源的默认申请/限制值,并且⾃动的在运⾏时注⼊到多个Container中。
LimitRange默认值可能⼩于客户端提交给API服务器的规约中为容器指定的request值导致Pod将⽆法调度
cat > myRange.yml <<-'EOF'
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-resource-constraint
spec:
limits:
- default:
cpu: "500m" # 默认限制值
defaultRequest:
cpu: "500m" # 默认请求值
max:
cpu: "1" # 最大值
min:
cpu: "100m" # 最小值
type: Container # 限制类型为容器
EOF
kubectl delete -f myRange.yml
kubectl apply -f myRange.yml
# K8s允许将CPU的限额设置为分数,⽐如CPU.limits=500m,500milliCPU,0.5个CPU,Pod就会被分到⼀个CPU⼀半计算能⼒。等价于cpu=0.5,不过官⽅推荐500m
# 内存资源的单位是bytes,⽀持使⽤Ei,Pi,Ti,Gi,Mi,Ki的⽅式作为bytes的值,要注意Mi和M的区别(1Mi=10241024,1M=10001000)。
# 声明CPU资源请求为700m但未声明limit的Pod:Pod将不会被调度,失败并出现类似以下的错误:
cat > conflict.yml <<-'EOF'
apiVersion: v1
kind: Pod
metadata:
name: example-conflict-with-limitrange-cpu
spec:
containers:
- name: demo
image: registry.k8s.io/pause:2.0
resources:
requests:
cpu: "700m"
EOF
kubectl delete -f conflict.yml
kubectl apply -f conflict.yml
Pod "example-conflict-with-limitrange-cpu" is invalid: spec.containers[0].resources.requests: Invalid value: "700m": must be less than or equal to cpu limit
# 如果你同时设置了request和limit,即使相同的LimitRange,新Pod也会被成功调度:
cat > conflict.yml <<-'EOF'
apiVersion: v1
kind: Pod
metadata:
name: example-no-conflict-with-limitrange-cpu
spec:
containers:
- name: demo
image: registry.k8s.io/pause:2.0
resources:
requests:
cpu: "700m"
limits:
cpu: "700m"
EOF
kubectl delete -f conflict.yml
kubectl apply -f conflict.yml
Resource Quota(资源配额)
资源配额,通过ResourceQuota对象来定义,对每个命名空间的资源消耗总量、某种类型的对象的总数⽬、Pod可以使⽤的计算资源提供限制
配额机制所⽀持的资源类型:

不同的团队可以在不同的命名空间下⼯作。通过RBAC强制执⾏。集群管理员可为每个命名空间创建⼀个或多个ResourceQuota对象。
当⽤户在命名空间下创建资源(如Pod、Service等)时,配额系统会跟踪集群的资源使⽤情况,确保使⽤的资源⽤量不超过ResourceQuota中定义的硬性资源限额。
如果资源创建或者更新请求违反了配额约束,那么该请求会报错(HTTP403FORBIDDEN),并在消息中给出有可能违反的约束。
如果命名空间下的计算资源cpu和memory的配额被启⽤,则必须设定请求值(request)和约束值(limit),否则配额系统将拒绝Pod的创建。可⽤LimitRanger准⼊控制器来为没有设置计算资源需求的Pod设置默认值
对于其他资源:⽆需为该资源设置限制或请求。如果资源配额限制了此命名空间的临时存储,则可以创建没有限制/请求临时存储的新Pod。可⽤限制范围⾃动设置对这些资源的默认请求
在具有32GiB内存和16核CPU资源的集群中,允许A团队⽤20GiB内存和10核的CPU资源,B团队⽤10GiB内存和4核的CPU资源,预留2GiB内存和2核的CPU资源供将来分配。限制"testing"命名空间使⽤1核CPU资源和1GiB内存。允许"production"命名空间使⽤任意数量
# 查看是否支持
kubectl api-resources | grep resourcequota
resourcequotas quota v1 true ResourceQuota
cat > helloworld.yml <<-'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: helloworld-deployment
namespace: myspace
spec:
replicas: 3
selector:
matchLabels:
app: helloworld
template:
metadata:
labels:
app: helloworld
spec:
containers:
- name: k8s-demo
image: 105552010/k8s-demo
ports:
- name: nodejs-port
containerPort: 3000
resources:
requests:
cpu: "200m"
memory: "512Mi"
limits:
cpu: "400m"
memory: "1Gi"
EOF
kubectl delete -f helloworld.yml
kubectl apply -f helloworld.yml
存储资源配额

如果针对"gold"storageclass与"bronze"storageclass设置配额可以定义如下配额:
gold.storageclass.storage.k8s.io/requests.storage:500Gi
bronze.storageclass.storage.k8s.io/requests.storage:100Gi
对象数量限定
cat > namespace-quota.yml <<-'EOF'
apiVersion: v1
kind: Namespace
metadata:
name: myspace
---
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quota
namespace: myspace
spec:
hard:
requests.cpu: "2"
requests.memory: "2Gi"
requests.nvidia.com/gpu: "2"
limits.cpu: "3"
limits.memory: "3Gi"
limits.nvidia.com/gpu: "3"
---
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-quota
namespace: myspace
spec:
hard:
configmaps: "10"
persistentvolumeclaims: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
services.loadbalancers: "2"
EOF
kubectl delete -f namespace-quota.yml
kubectl apply -f namespace-quota.yml
# 部署pod
cat > myworld.yml <<-'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: helloworld-deployment
namespace: myspace
spec:
replicas: 3
selector:
matchLabels:
app: helloworld
template:
metadata:
labels:
app: helloworld
spec:
containers:
- name: k8s-demo
image: 105552010/k8s-demo
ports:
- name: nodejs-port
containerPort: 3000
EOF
kubectl delete -f myworld.yml
kubectl apply -f myworld.yml
# 查看状态,所有pod未启动
kubectl get all -n myspace
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/helloworld-deployment 0/3 0 0 16s
NAME DESIRED CURRENT READY AGE
replicaset.apps/helloworld-deployment-7d47d68456 3 0 0 16s
# 查看明细
kubectl describe replicaset.apps/helloworld-deployment-7d47d68456 -n myspace
Warning FailedCreate 39s replicaset-controller Error creating: pods "helloworld-deployment-7d47d68456-jg72f" is forbidden: failed quota: compute-quota: must specify limits.cpu for: k8s-demo; limits.memory for: k8s-demo; requests.cpu for: k8s-demo; requests.memory for: k8s-demo
# myspace命名空间下所有pod在部署时必须指定资源,否则不予分配
limits.cpu
limits.memory
requests.cpu
requests.memory
# 调整后设置限定与需求数量
cat > myworld.yml <<-'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: helloworld-deployment
namespace: myspace
spec:
replicas: 3
selector:
matchLabels:
app: helloworld
template:
metadata:
labels:
app: helloworld
spec:
containers:
- name: k8s-demo
image: 105552010/k8s-demo
ports:
- name: nodejs-port
containerPort: 3000
resources:
requests:
cpu: "100m"
memory: "0.5Gi"
limits:
cpu: "200m"
memory: "0.5Gi"
EOF
kubectl delete -f myworld.yml
kubectl apply -f myworld.yml
# 有⼀个pod没有启动,看明细
kubectl get all -n myspace
# 检查限定明细
kubectl get resourcequotas -n myspace
kubectl describe resourcequotas -n myspace
Name: compute-quota
Namespace: myspace
Resource Used Hard
-------- ---- ----
limits.cpu 800m 2
limits.memory 2Gi 2Gi
limits.nvidia.com/gpu 0 2
requests.cpu 400m 1
requests.memory 1Gi 1Gi
requests.nvidia.com/gpu 0 1
Name: object-quota
Namespace: myspace
Resource Used Hard
-------- ---- ----
configmaps 1 10
persistentvolumeclaims 0 4
replicationcontrollers 0 20
secrets 0 10
services 0 10
services.loadbalancers 0 2
# 检查pod状态
kubectl describe replicasets.apps -n myspace
Warning FailedCreate 88s replicaset-controller Error creating: pods "helloworld-deployment-7c77885d8f-2kh6t" is forbidden: exceeded quota: compute-quota, requested: limits.memory=1Gi,requests.memory=512Mi, used: limits.memory=2Gi,requests.memory=1Gi, limited: limits.memory=2Gi,requests.memory=1Gi
# 确实内存不够分配
Deployment控制器,零停机保障-滚动更新策略与设置,扩容缩容,回滚部署到指定版本
应用程序源码被编译打包为容器,并被装入Pod中。但Pod没有自愈能力,不能扩缩容,不支持方便的升级和回滚。
Deployment提供了扩缩容管理、不停机更新以及版本控制、无缝迁移、自动灾难恢复、一键回滚等特性。用于部署无状态服务,是Pod控制器,管理多个Pod,如注册中心、网关、SpringBoot框架等
用户通过上层控制器来完成Pod部署。包括Deployment、DaemonSet以及StatefulSet
Deployment在底层利用了ReplicaSet的对象。但不建议直接操作ReplicaSet(自愈、扩展性)
Replication Controller(RC):可以使Pod副本数达到指定数量,确保一个Pod或者一组同类Pod总是可用的。使用RC维护的Pod在失败、删除、终止时会自动替换,用来监视多个节点上的多个Pod
ReplicaSet(RS):支持基于集合的标签选择器的新一代RC,主要作用于Deployment协调创建、删除、更新Pod,和RC的区别是,RS支持标签选择器,可以单独使用,但一般用Deployment来自动管理RS,除非自定义的Pod不需要更新或者其他编排等
yml构建Deploymemnt部署脚本
mkdir /etc/k8s
cat > /etc/k8s/deploy-nginx.yaml <<-'EOF'
# 组/版本
apiVersion: apps/v1
# 对象类型
kind: Deployment
# 元数据:定义API对象名字和标签
metadata:
#部署名称
name: deploy-nginx
# 规范。对象资源的配置信息
spec:
#spec.selector表明Deployment要管理的Pod所必须具备的标签
selector:
#匹配所有标签app且值为nginx
matchLabels:
app: nginx
#replicas 部署多少个Pod副本
#replicas: 5
strategy:
#使⽤滚动更新策略升级
type: RollingUpdate
rollingUpdate:
#最多允许出现1个不可⽤pod
maxUnavailable: 1
#不允许溢出,Pod总量最多只能5个
maxSurge: 1
#滚动更新动作间隔10s
minReadySeconds: 10
#spec.template 定义了Deployment管理的Pod模板
template:
#元数据定义每一个POD拥有标签 key=app,value=nginx
metadata:
labels:
app: nginx
#template.spec说明具体部署的pod容器与镜像信息
spec:
containers:
#容器名
- name: container-nginx
#镜像名称
image: nginx:1.20.2-alpine
#容器对外暴露的端口号
ports:
- containerPort: 80
EOF
kubectl delete -f /etc/k8s/deploy-nginx.yaml
kubectl apply -f /etc/k8s/deploy-nginx.yaml
# 获取目前所有部署概况
kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
deploy-nginx 4/4 4 4 14h
NAME:Deployment名称
READY:Pod就绪个数和总副本数
UP-TO-DATE:显示已达到期望状态的被更新的副本数
AVAILABLE:显示用户可以使用的应用程序副本数,当前为0,说明目前还没有达到期望的Pod;
AGE:程序运行时间
# 查看具体部署详情
kubectl describe deploy deploy-nginx
kubectl get pods -o wide --show-labels
kubectl describe pod deploy-nginx-774c78fcfc-4z9hn
# 查看滚动更新进度
kubectl rollout status deploy deploy-nginx
- K8s支持RollingUpdate策略以逐渐用新pod替换旧pod,同时继续为客户端提供服务而不会导致停机
- 没有原始的YAML文档时,kubectl edit deploy deploy-nginx --record
- 拥有原始YAML文档时,滚动更新期望状态是Pod数量为4个副本,maxSurge:1是在更新过程中,Pod数量不超过4+1=5个,而maxUnavailable:1同一时间可用状态POD最多为4-1=3个。结果是在滚动更新的过程中最多只能同时更新5-3=2个Pod
扩缩容
# scale静态扩缩容
kubectl scale deploy deploy-nginx --replicas=4
# kube-scheduler调度:默认使用,pod自动分配到不同的节点
回滚版本
kubectl apply -f /etc/k8s/deploy-nginx-v.1.20.yaml --record
kubectl apply -f /etc/k8s/deploy-nginx-v.1.21.yaml --record
kubectl apply -f /etc/k8s/deploy-nginx-v.1.22.yaml --record
# 查看版本历史
kubectl rollout history deploy deploy-nginx
REVISION CHANGE-CAUSE
1 kubectl apply --filename=/etc/k8s/deploy-nginx-v.1.20.yaml --record=true
2 kubectl apply --filename=/etc/k8s/deploy-nginx-v.1.21.yaml --record=true
3 kubectl apply --filename=/etc/k8s/deploy-nginx-v.1.22.yaml --record=true
# 回滚到指定版本,
# 回滚后版本号会变最大,原来的版本号消失
kubectl rollout undo deploy deploy-nginx --to-revision=1
# 回滚1和4后
kubectl rollout history deploy deploy-nginx
deployment.apps/deploy-nginx
REVISION CHANGE-CAUSE
2 kubectl apply --filename=/etc/k8s/deploy-nginx-v.1.21.yaml --record=true
3 kubectl apply --filename=/etc/k8s/deploy-nginx-v.1.22.yaml --record=true
5 kubectl apply --filename=/etc/k8s/deploy-nginx-v.1.20.yaml --record=true
6 kubectl apply --filename=/etc/k8s/deploy-nginx-v.1.23.yaml --record=true
#yaml格式看所有历史版本yaml格式信息
kubectl rollout history deploy deploy-nginx -o yaml
#yaml格式看指定历史版本yaml格式信息
kubectl rollout history deploy deploy-nginx -o yaml --revision=3
#yaml格式导出指定历史版本yaml格式信息到指定文件
kubectl rollout history deploy deploy-nginx -o yaml --revision=3 > deploy-nginx-version-3.yaml
利用DaemonSet为新节点自动部署Pod

- DaemonSet当有节点加入集群时,也会新增一个Pod。有节点从集群移除时,Pod会被回收。删除DaemonSet将会删除它创建的所有Pod
# 为每一个节点自动部署一个Pod自动对外暴露Nginx服务,利用hostNetwork选项IP地址将变为真实节点IP
mkdir /etc/k8s
cd /etc/k8s
cat > ds-nginx.yaml <<-'EOF'
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ds-nginx
spec:
# 选择app=nginx标签的pod
selector:
matchLabels:
app: nginx
# 定义由控制器创建的 Pod 的标签
template:
metadata:
labels:
app: nginx
spec:
hostNetwork: true
containers:
- name: nginx
image: nginx:1.20.2-alpine
ports:
- containerPort: 80
EOF
kubectl delete -f ds-nginx.yaml
kubectl apply -f ds-nginx.yaml
kubectl get pods -o wide
Service控制器、作用,YAML定义Service,Service四种服务类型,Service与Kube-Proxy实现原理
- Service提供了一个稳定的服务名称与IP地址、端口、DNS,提供基组动态Pod集合的TCP以及UDP负载均衡能力。集群内不同应⽤之间可通过DNS相互访问
- 直接与独⽴的Pod进⾏通信是不明智的,因为Pod的IP地址不可靠。因为Pod可能在扩容、升级、回滚或发⽣故障等过程中失效。被新pod替代
- Service与Pod之间、Deployment和Pod之间通过Label和Label筛选器(selector)松耦合。
mkdir /etc/k8s
cat > /etc/k8s/deploy-nginx.yaml <<-'EOF'
#使用的API版本。最新版Kubernetes位于apps/v1的API组
apiVersion: apps/v1
#kind告诉Kubernetes现在定义的是一个Deployment对象
kind: Deployment
#metadata部分定义Deployment的名字和标签
metadata:
#部署名称为
name: deploy-nginx
#spec下的内容都与Pod有关
spec:
#spec.selector表明Deployment要管理的Pod所必须具备的标签
selector:
#匹配所有标签app且值为nginx
matchLabels:
app: nginx
#replicas告诉Kubernetes需要部署多少个Pod副本
replicas: 4
#spec.template下的内容定义了Deployment管理的Pod模板
template:
#元数据定义每一个POD拥有标签 key=app,value=nginx
metadata:
labels:
app: nginx
#template.spec说明具体部署的容器与镜像信息
spec:
containers:
#容器名
- name: container-nginx
#镜像名称
image: nginx:1.20.2-alpine
#容器对外暴露的端口号
ports:
- containerPort: 80
EOF
kubectl delete deploy deploy-nginx
kubectl apply -f /etc/k8s/deploy-nginx.yaml
kubectl get deploy
kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
deploy-nginx-7fcfb9c499-64fdq 1/1 Running 0 14h app=nginx,pod-template-hash=7fcfb9c499
deploy-nginx-7fcfb9c499-9478t 1/1 Running 0 14h app=nginx,pod-template-hash=7fcfb9c499
deploy-nginx-7fcfb9c499-smcl2 1/1 Running 0 14h app=nginx,pod-template-hash=7fcfb9c499
deploy-nginx-7fcfb9c499-vvq6s 1/1 Running 0 14h app=nginx,pod-template-hash=7fcfb9c499
mkdir /etc/k8s
cat > /etc/k8s/svc-nginx.yaml <<-'EOF'
apiVersion: v1
#描述对象为Service
kind: Service
#定义Service的名称
metadata:
name: svc-nginx
#配置细节
spec:
#通过节点端口对外暴露
type: NodePort
#选择器,选中所有app=nginx的pod
selector:
app: nginx
#端口信息
ports:
#Service在集群内部对外暴露的端口
- port: 8000
#容器内对外暴露的端口
targetPort: 80
#节点对外暴露的端口
nodePort: 30001
EOF
kubectl delete svc svc-nginx
kubectl apply -f /etc/k8s/svc-nginx.yaml
kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 172.16.32.1 <none> 443/TCP 4d2h <none>
nginx-deployment NodePort 172.16.32.46 <none> 9000:31090/TCP 4d2h app=nginx
svc-nginx NodePort 172.16.32.87 <none> 8000:30000/TCP 19s app=my-nginx
kubectl describe svc svc-nginx
Name: svc-nginx
Namespace: default
Labels: <none>
Annotations: <none>
Selector: app=my-nginx
Type: NodePort
IP Family Policy: SingleStack
IP Families: IPv4
IP: 172.16.32.87
IPs: 172.16.32.87
Port: <unset> 8000/TCP
TargetPort: 80/TCP
NodePort: <unset> 30000/TCP
Endpoints: 172.16.10.246:80,172.16.10.85:80,172.16.10.87:80
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>
# 扩缩容Endpoints会增多
Service四种服务类型
ClusterIP(默认)
- 为ClusterIP服务分配一个集群内部ip地址。
- 服务只能在集群内访问。不能从集群外部请求服务pod
apiVersion: v1
kind: Service
metadata:
name: my-backend-service
spec:
type: ClusterIP # Optional field (default)
clusterIP: 10.10.0.1 # within service cluster ip range
ports:
- name: http
protocol: TCP
port: 80
targetPort: 8080
NodePort
- 自动创建节点端口服务(30000-32767)路由到的ClusterIP服务。
apiVersion: v1
kind: Service
metadata:
name: my-frontend-service
spec:
type: NodePort
selector:
app: web
ports:
- name: http
protocol: TCP
port: 80
targetPort: 8080
nodePort: 30000 # 30000-32767, Optional field
LoadBalancer
- NodePort服务的扩展。自动创建外部负载均衡器路由到的NodePort和ClusterIP服务。
- 将NodePort与基于云环境的负载器集成在一起。
- 云提供商 (AWS、Azure、GCP等) 提供自己的本机负载均衡器实现,然后自动将请求路由到K8s服务。
- 每次要向外界公开服务时,都必须创建一个新的LoadBalancer并获取ip地址。
apiVersion: v1
kind: Service
metadata:
name: my-frontend-service
spec:
type: LoadBalancer
clusterIP: 10.0.171.123
loadBalancerIP: 123.123.123.123
selector:
app: web
ports:
- name: http
protocol: TCP
port: 80
targetPort: 8080
ExternalName
- 将服务映射到DNS名称
- 它通过返回CNAME记录及其值,将服务映射到externalName字段的内容 (x.com)。它不会建立任何形式的代理
- 用创建服务表示外部数据存储,例如在K8s外部运行的数据库。用ExternalName服务 (作为本地服务) 当pod从一个命名空间与另一个命名空间中的服务通讯
apiVersion: v1
kind: Service
metadata:
name: svc-app
spec:
type: ExternalName
externalName: svc-mysql.ns-db.svc.cluster.local
Service与Kube-Proxy实现原理
- kube-proxy在每个节点上运行。可以执行TCP、UDP 和 SCTP 流转发
- kube-proxy在默认的iptables模式下,会为每个Service添加iptables规则,捕获流向Service的ClusterIP和端口的流量,并通过负载均衡策略(如轮询)将流量重定向到Service后端集合中的一个Endpoint(Pod),使用iptables处理流量的系统开销低,因为流量由Linux netfilter处理,无需在用户空间和内核空间之间切换
k8s命令行工具安装(必须)
# 下载包
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
# 安装
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
# 测试
kubectl version --client
k8sminikube(学习环境)
linux代理
docker代理
轻量级的单节点的kubernetes集群环境
# 前提先按装docker、containerd等并启动,2xCPU,4G内存,20G磁盘
# 安装minikube
curl -LO https://github.com/kubernetes/minikube/releases/latest/download/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube && rm -f minikube-linux-amd64
# 启动minikube,VMware情况下 --force
# 无外网 --image-mirror-country='cn'
# 设置代理参考Linux 宿主机开通192.168.1.0/24的子网防火墙
# --cpu=4防止ingress插件启用失败 --addons=ingress启动网关
/usr/local/bin/minikube start --cpus=4 --force --memory=8192m --insecure-registry="192.168.1.155:80" --addons=ingress --driver=docker --registry-mirror="https://docker.m.daocloud.io"
# 安装kubectl
minikube kubectl -- get pods -A
# 检查是否安装成功
minikube
# 报错1:因 GUEST_MISSING_CONNTRACK 错误而退出:抱歉, Kubernetes 1.31.0 要求在 root 路径安装 crictl
# VERSION="v1.31.0" # 替换为实际版本
# wget https://github.com/kubernetes-sigs/cri-tools/releases/download/$VERSION/crictl-$VERSION-linux-amd64.tar.gz
# sudo tar -zxvf crictl-$VERSION-linux-amd64.tar.gz -C /usr/bin/
# sudo chmod +x /usr/bin/crictl
# crictl --version
# 报错2:Kubernetes v1.24+ 和 docker 容器运行时的 none 驱动需要 cri-dockerd。
#wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.16/cri-dockerd-0.3.16.amd64.tgz
#tar xf cri-dockerd-0.3.16.amd64.tgz
#cd cri-dockerd
#install -o root -g root -m 0755 cri-dockerd /usr/local/bin/cri-dockerd
# 报错3:The none driver with Kubernetes v1.24+ requires containernetworking-plugins.
#CNI_PLUGIN_VERSION="v1.34"
#CNI_PLUGIN_TAR="cni-plugins-linux-amd64-$CNI_PLUGIN_VERSION.tgz" # change arch if not on amd64
#CNI_PLUGIN_INSTALL_DIR="/opt/cni/bin"
#curl -LO "https://github.com/containernetworking/plugins/releases/download/$CNI_PLUGIN_VERSION/$CNI_PLUGIN_TAR"
#sudo mkdir -p "$CNI_PLUGIN_INSTALL_DIR"
#sudo tar -xf "$CNI_PLUGIN_TAR" -C "$CNI_PLUGIN_INSTALL_DIR"
#rm "$CNI_PLUGIN_TAR"
# 删除所有 Pod 和关联的 Controller
kubectl delete all --all --all-namespaces
k8s安装(生产环境)
- 配置需求:4核8G\40G硬盘、可联通外网
- 基准节点CentOS 7.6(内核4.19) & Containerd 用户名 / 密码:root / root
- 环境说明
- 1个Master节点,2个Worknode节点
- POD地址段:172.16.10.0/24 (172.16.10.0~255)学习环境最多部署255个POD
- Service地址段:172.16.32.0/24 (172.16.32.0~255)学习环境最多部署255个Service
- 所有k8s主机安装Containerd
# 安装Docker 20.10版本,内置Containerd
yum install docker-ce-20.10.* docker-ce-cli-20.10.* -y
# 启用自动containerd.conf的应用模块
cat <<EOF | sudo tee /etc/modules-load.d/containerd.conf
overlay
br_netfilter
EOF
modprobe -- overlay
modprobe -- br_netfilter
# 设置网络参数,开启iptable桥接模式与ip_forward转发
cat <<EOF | sudo tee /etc/sysctl.d/99-kubernetes-cri.conf
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
EOF
# CentOS系统配置生效
sysctl --system
# 生成containerd的默认配置文件路径:/etc/containerd/config.toml
mkdir -p /etc/containerd
containerd config default | tee /etc/containerd/config.toml
# 搜索containerd.runtimes.runc.options,添加SystemdCgroup = true
# 搜索sandbox_image,将值改为 registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6
vim /etc/containerd/config.toml
# 重载配置文件,并设置containerd自动启动
systemctl daemon-reload
systemctl enable --now containerd
# 添加对外暴露的sock端点,K8S通过该端点与containerd交互
cat > /etc/crictl.yaml <<EOF
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF
- 主节点安装
# 查看本地IP地址
ifconfig
# 设置主机名称
hostnamectl set-hostname master0
# 安装k8s
yum install kubeadm-1.26* kubelet-1.26* kubectl-1.26* -y
# 配置k8s
export LOCAL_IP=192.168.31.220
echo $LOCAL_IP
mkdir /etc/k8s
cd /etc/k8s
rm -f kubeadm-config.yaml
wget http://manongbiji.oss-cn-beijing.aliyuncs.com/ittailkshow/k8s/download/kubeadm-config.yaml
sed -i 's/{LOCAL_IP}/'$LOCAL_IP'/' kubeadm-config.yaml
cd /etc/k8s
kubeadm config migrate --old-config kubeadm-config.yaml --new-config new.yaml
# k8s开机自启动
systemctl start kubelet
systemctl enable kubelet
# 可选
kubeadm config images pull --config /etc/k8s/new.yaml
kubeadm init --config /etc/k8s/new.yaml --upload-certs
# 执行完出现下面这几句
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
===========================================================
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
===========================================================
Alternatively, if you are the root user, you can run:
=======================================================
export KUBECONFIG=/etc/kubernetes/admin.conf
=======================================================
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
================================================================
kubeadm join 192.168.31.104:6443 --token 7t2weq.bjbawausm0jaxury \
--discovery-token-ca-cert-hash sha256:07db227ea83f8e777ffb0d8c9adc0f4999b52af1ce432d4072eb454bf73c5bff \
--control-plane --certificate-key 65961cc166a8d09910ac90849efa6121e91e87d8472aeafe1462a0f295a7c94e
============================================================================
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
# 安装失败清除脚本
kubeadm reset -f
ipvsadm --clear
rm -rf ~/.kube
# 主节点执行(上面k8s启动成功时)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf
cat >> /etc/profile <<-'EOF'
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
- 工作节点 * 2
# 分别设置主机名
hostnamectl set-hostname node0
hostnamectl set-hostname node1
# 安装Kubeadm
yum install kubeadm-1.26* kubelet-1.26* kubectl-1.26* -y
# 加入节点
kubeadm join 192.168.31.220:6443 --token 7t2weq.bjbawausm0jaxury \
--discovery-token-ca-cert-hash sha256:e180599ac5957eb5989dc9961d8252ff316c9df53492e76f3d4533695c4f555b
# 设置自动重启
systemctl start kubelet
systemctl enable kubelet
# 主节点安装Calico网络插件,使主从节点的状态status进入ready
mkdir /etc/k8s
cd /etc/k8s
rm -f calico.yaml
wget http://manongbiji.oss-cn-beijing.aliyuncs.com/ittailkshow/k8s/download/calico.yaml
kubectl delete -f calico.yaml
kubectl apply -f calico.yaml
# 查看节点
kubectl get nodes -A -o wide
# 查看pod
kubectl get pods -A -o wide
# 查看service
kubectl get services -A -o wide
# 主节点执行测试脚本
# 测试用部署脚本
mkdir /etc/k8s
cd /etc/k8s
rm -f nginx-dep.yml
wget http://manongbiji.oss-cn-beijing.aliyuncs.com/ittailkshow/k8s/download/nginx-dep.yml
kubectl delete deploy nginx-deployment
kubectl delete -f nginx-dep.yml
kubectl apply -f nginx-dep.yml
kubectl get deploy -o wide
# 测试用服务脚本
mkdir /etc/k8s
cd /etc/k8s
rm -f nginx-srv.yml
wget http://manongbiji.oss-cn-beijing.aliyuncs.com/ittailkshow/k8s/download/nginx-srv.yml
kubectl delete srv nginx-deployment
kubectl delete -f nginx-srv.yml
kubectl apply -f nginx-srv.yml
kubectl get service
http://192.168.31.105:31090
常用命令
- 基础命令
# 查看帮助
kubectl --help
# 查看API版本
kubectl api-versions
# 查看集群信息
kubectl cluster-info
- 资源的创建和运行
# 创建并运行一个指定的镜像
kubectl run NAME --image=image [params...]
# e.g. 创建并运行一个名字为nginx的Pod外部访问不了(不推荐,推荐使用deployment等)
kubectl run nginx --image=nginx --port=80
# create只创建一次资源,apply创建并更新资源
# 根据YAML配置文件或者标准输入创建资源
kubectl create RESOURCE
# e.g.
# 根据nginx.yaml配置文件创建资源
kubectl create -f nginx.yaml
# 根据URL创建资源
kubectl create -f https://k8s.io/examples/application/deployment.yaml
# 根据目录下的所有配置文件创建资源
kubectl create -f ./dir
# 创建deployment(命名:deploymentID-replicasetID-podID)
kubectl create deployment nginx-deployment --image=nginx
# 通过文件名或标准输入配置资源
kubectl apply -f (-k DIRECTORY | -f FILENAME | stdin)
# e.g.
# 根据nginx.yaml配置文件创建资源
kubectl apply -f nginx.yaml
- 查看资源信息
# 查看集群中某一类型的资源
kubectl get RESOURCE [-A -o wide]
# 其中,RESOURCE可以是以下类型:
kubectl get pods / po # 查看Pod --show-labels
kubectl get services / svc # 查看Service
kubectl get deployment/deploy # 查看Deployment
kubectl get replicaset /rs # 查看ReplicaSet
kubectl get cm # 查看ConfigMap
kubectl get secret # 查看Secret
kubectl get ing # 查看Ingress
kubectl get pv # 查看PersistentVolume
kubectl get pvc # 查看PersistentVolumeClaim
kubectl get ns # 查看Namespace
kubectl get node # 查看Node
kubectl get all # 查看所有资源
# 后面还可以加上 -o wide 参数来查看更多信息
kubectl get pods -o wide
# 查看某一类型资源的详细信息
kubectl describe RESOURCE NAME
# e.g. 查看名字为nginx的Pod的详细信息
kubectl describe pod nginx
- 资源的修改、删除和清理
# 更新某个资源的标签
kubectl label RESOURCE NAME KEY_1=VALUE_1 ... KEY_N=VALUE_N
# e.g. 更新名字为nginx的Pod的标签
kubectl label pod nginx app=nginx
# 删除某个资源
kubectl delete RESOURCE NAME
# e.g. 删除名字为nginx的Pod
kubectl delete pod nginx
# e.g. 删除deployment
kubectl delete deployment nginx-deployment
# 删除某个资源的所有实例
kubectl delete RESOURCE --all
# e.g. 删除所有Pod
kubectl delete pod --all
# 根据YAML配置文件删除资源
kubectl delete -f FILENAME
# e.g. 根据nginx.yaml配置文件删除资源
kubectl delete -f nginx.yaml
# 设置某个资源的副本数
kubectl scale --replicas=COUNT RESOURCE NAME
# e.g. 设置名字为nginx的Deployment的副本数为3
kubectl scale --replicas=3 deployment/nginx
# 根据配置文件或者标准输入替换某个资源
kubectl replace -f FILENAME
# e.g. 根据nginx.yaml配置文件替换名字为nginx的Deployment
kubectl replace -f nginx.yaml
- 调试和交互
# 进入某个Pod的容器中
kubectl exec [-it] POD [-c CONTAINER] -- COMMAND [args...]
# e.g. 进入名字为nginx的Pod的容器中,并执行/bin/bash命令
kubectl exec -it nginx -- /bin/bash
# 编辑deployment配置文件(不常用) 修改replicas wq保存后更新自动生效不用手动重启
kubectl edit deployment nignx-deployment
# 查看某个Pod的日志
kubectl logs [-f] [-p] [-c CONTAINER] POD [-n NAMESPACE]
# e.g. 查看名字为nginx的Pod的日志
kubectl logs nginx
# 查看deployment日志
kubectl logs nignx-deployment
# 将某个Pod的端口转发到本地
kubectl port-forward POD [LOCAL_PORT:]REMOTE_PORT [...[LOCAL_PORT_N:]REMOTE_PORT_N]
# e.g. 将名字为nginx的Pod的80端口转发到本地的8080端口
kubectl port-forward nginx 8080:80
# 连接到现有的某个Pod(将某个Pod的标准输入输出转发到本地)
kubectl attach POD -c CONTAINER
# e.g. 将名字为nginx的Pod的标准输入输出转发到本地
kubectl attach nginx
# 运行某个Pod的命令
kubectl run NAME --image=image -- COMMAND [args...]
# e.g. 运行名字为nginx的Pod
kubectl run nginx --image=nginx -- /bin/bash
Endpoints与Endpointslice端点切⽚的作⽤。使⽤Service和Endpointslice接⼊三⽅外部应⽤
Endpoints用于存储与Service的selector关联的Pod的IP地址和端口信息。为了追踪PodIP变化进⾏负载均衡
在Service创建时根据selector关联⼀个Endpoints资源,如果Service没有定义selector字段,将不会⾃动创建Endpoints。
Endpoints是资源对象,存储在etcd中,具有容量限制,如果某个Endpoints资源中端⼝的个数超过1000会被截断。kube-controller-manager[1]的--maxendpoints-per-slice标志设置
在⼤流量场景下,Pod数量不断增多,Endpoints也将变得越⼤。其中⼀个端点发⽣了变更,将会导致整个Endpoints资源更新。Endpoints API局限性变为性能瓶颈。因此1.21+引⼊Endpointslice API,它将Service所有Endpoints分片存储,每个EndpointSlice只包含部分(默认100) Pod的地址和端口信息。提供了可扩展和可伸缩的能⼒。(默认启用)
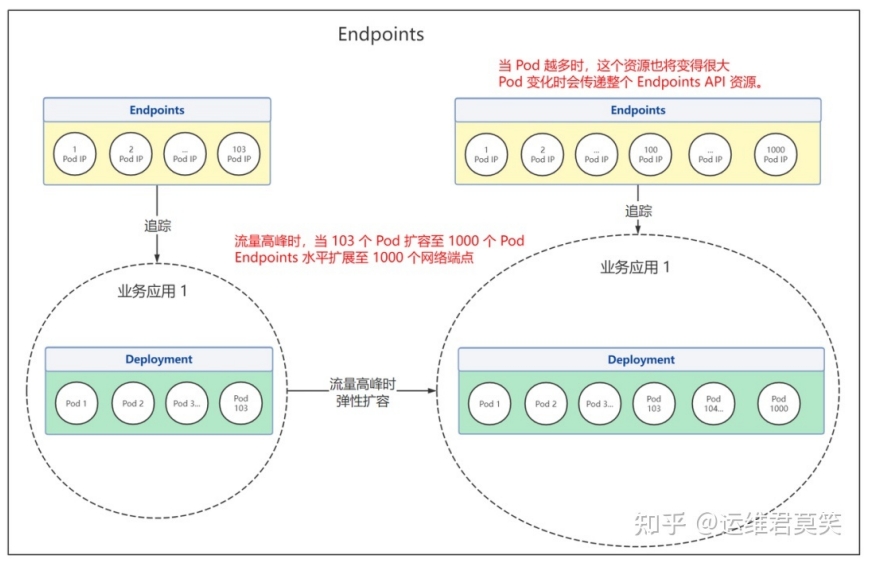
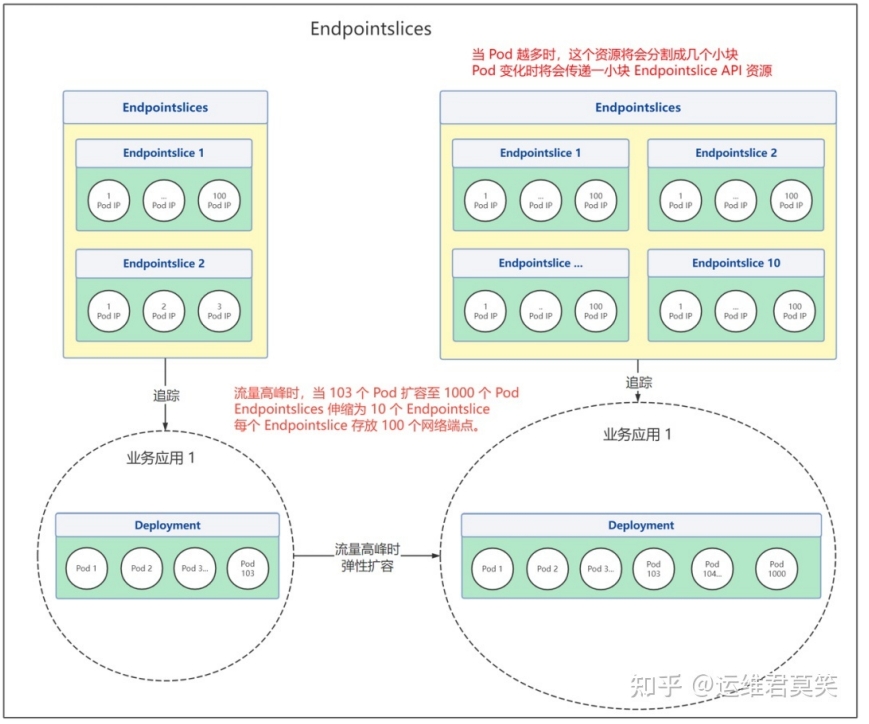
Endpoints场景:有弹性伸缩需求,Pod数量较少,传递资源不会造成⼤量⽹络流量和额外处理。⽆弹性伸缩需求,Pod数量不会太多。哪怕Pod数量是固定,但是总是要滚动更新或者出现故障的。
Endpointslice场景:有弹性需求,且Pod数量较多(⼏百上千)。Pod数量很多(⼏百上千),Endpoints⽹络端点超过最⼤数量限制1000
kubectl get endpoints
kubectl get endpointslice
kubectl describe endpointslice svc-nginx-sgnzf
使⽤Service+Endpointslice屏蔽外部环境细节,接⼊三⽅外部应⽤(如MySQL)
# 定义Service,因为MySQL不属于K8S管理范畴,因此⽆法⽤selector进⾏匹配
mkdir/etc/k8s
cat>/etc/k8s/svc-mysql.yaml<<-'EOF'
apiVersion:v1
#描述对象为Service
kind:Service
#定义Service的名称
metadata:
name:svc-mysql
#配置细节
spec:
#通过节点端⼝对外暴露
type:NodePort
#端⼝信息
ports:
# Service在集群内部对外暴露的端⼝
- port:8306
# 容器内程序运行的端⼝
targetPort:3306
# 节点对外暴露的端⼝
nodePort:30001
EOF
kubectl delete svc svc-mysql
kubectl apply -f /etc/k8s/svc-mysql.yaml
# 定义⼀个Endpointslice,指向外部应⽤,在Endpointlice⼀侧绑定服务名svc-mysql
mkdir/etc/k8s
cat>/etc/k8s/svc-mysql-eps.yaml<<-'EOF'
apiVersion:discovery.k8s.io/v1
kind:EndpointSlice
metadata:
name:svc-mysql-eps
labels:
kubernetes.io/service-name:svc-mysql
addressType:IPv4
ports:
- name:''
appProtocol:http
protocol:TCP
port:3306
endpoints:
- addresses:
- "192.168.31.103"
EOF
cd/etc/k8s
kubectl delete endpointslice svc-mysql-eps
kubectl apply -f /etc/k8s/svc-mysql-eps.yaml
kubectl get endpointslice
NAME ADDRESS TYPE PORTSENDPOINTS AGE
kubernetes IPv4 6443 192.168.31.220 6d18h
svc-mysql-eps IPv4 3306 192.168.31.103 6m50s
Ingress与Ingress Controller
- Ingress是⼀个对象,用于管理集群中服务(Service)的外部访问,可以定义⼊站和出站规则集中管理路由,支持HTTP和HTTPS
Kubernetes Ingress vs LoadBalancer vs NodePort
- NodePort是Service类型在YAML中的配置。在每个节点上向该服务分配⼀个特定的端⼝,并且对该端⼝上的群集的任何请求都将转发给该服务。缺点是每⼀个NodePort只能绑定⼀个Service,存在端口浪费
- LoadBalancer:将Service设置为LoadBalancer。集群中需要有云提供商提供外部负载均衡器功能。具有可⽤于访问服务的ip地址。每次要向外界公开服务时,都必须创建⼀个新的LoadBalancer并获取ip地址。
- Ingress:与Service完全独⽴的资源。可以将路由规则整合到⼀起。缺点必须配置⼀个Ingress Controller
Ingress Controller
使用Ingress时必需安装,负责将Ingress规则转化为底层网络配置,是一个部署在集群中的负载均衡器,不随集群⾃动启动。⽬前⽀持和维护AWS、GCE和Nginx Ingress控制器。
其他控制器(非官方)
- AKS应⽤程序⽹关Ingress控制器:配置Azure应⽤程序⽹关的Ingress控制器。
- Apache APISIX Ingress控制器:基于ApacheAPISIX⽹关的Ingress控制器。
- HAProxy Ingress:针对HAProxy的Ingress控制器。
- Istio Ingress:基于Istio的Ingress控制器。
- Kong Ingress控制器:⽤来驱动Kong Gateway的Ingress控制器。
- NGINX Ingress控制器:能够与NGINX⽹⻚ 服务器(作为代理)⼀起使⽤。
安装部署Ingress-Nginx
# 不是minikube安装ingress
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.5.1/deploy/static/provider/baremetal/deploy.yaml
# laoqi自动将image: registry.k8s.io/ingress-nginx/controller:v1.5.1@sha256:4ba73c697770664c1e00e9f968de14e08f606ff961c76e5d7033a4a9c593c629
# 改为:image: anjia0532/google-containers.ingress-nginx.controller:v1.5.1
kubectl apply -f http://manongbiji.oss-cn-beijing.aliyuncs.com/ittailkshow/k8s/download/ingress-nginx-1.5.1.yaml
kubectl delete -f http://manongbiji.oss-cn-beijing.aliyuncs.com/ittailkshow/k8s/download/ingress-nginx-1.5.1.yaml
# minikube安装ingress插件
minikube addons enable ingress
# 查看ingress插件是否enable
minikube addons list
# 出现如下状态表示安装成功
kubectl get po -A
ingress-nginx ingress-nginx-admission-create-n8p59 0/1 Completed 0 93m
ingress-nginx ingress-nginx-admission-patch-tc6gf 0/1 Completed 0 93m
ingress-nginx ingress-nginx-controller-66f74646d6-8vd8v 1/1 Running 0 55m
# 查看端口
kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.100.72.74 <none> 80:31403/TCP,443:31279/TCP 108m
ingress-nginx-controller-admission ClusterIP 10.107.1.45 <none> 443/TCP 108m
# 查看ip
minikube ip
192.168.49.2
# 测试
minikube service ingress-nginx-controller -n ingress-nginx --url
curl 192.168.49.2:31403
# 删除校验(本地环境)
kubectl get validatingwebhookconfigurations
NAME WEBHOOKS AGE
ingress-nginx-admission 1 76m
kubectl delete -A ValidatingWebhookConfiguration ingress-nginx-admission-tengine-controller
- YAML创建Ingress路由规则
rules.host
host是完全限定域名。⼊站请求在通过IngressRuleValue处理之前先进⾏host匹配。如果主机未指定,Ingress将根据指定的IngressRuleValue规则路由所有流量。
host可以是"通配符",如".foo.com")。通配符"*"必须单独显示为第⼀个DNS标签,并且仅与单个标签匹配。不能单独使⽤通配符作为标签(如Host="*")。请求将按以下⽅式与主机字段匹配:
如果host是精确匹配的,则如果http Host标头等于host值,则请求与此规则匹配。
如果host是⽤通配符给出的,那么如果HTTP Host标头与通配符规则的后缀(删除第⼀个标签)相同,则请求与此规则匹配。
rules.http.paths.pathType
pathType:决定如何解释path匹配
- Exact:与URL路径完全匹配。
- Prefix:根据按“/”拆分的URL路径前缀进⾏匹配。按路径元素逐个元素完成。路径元素引⽤的是路径中由“/”分隔符拆分的标签列表。如果每个p都是请求路径p的元素前缀,则请求与路径p匹配。如果路径的最后⼀个元素是请求路径中的最后⼀个元素的⼦字符串,则匹配不成功(例如/foo/bar匹配/foo/bar/baz,但不匹配/foo/barbaz)。
- ImplementationSpecific:路径匹配的解释取决于IngressClass。实现可以将其视为单独的路径类型,也可以将其视为前缀或确切的路径类型。实现需要⽀持所有路径类型。
rewrite-target
mkdir/etc/k8s
cd/etc/k8s
cat>svc-apple.yaml<<-'EOF'
apiVersion: v1
kind: Pod
metadata:
name: pod-apple
labels:
app: apple
spec:
containers:
- name: pod-apple
image: hashicorp/http-echo
args:
- "-text=apple"
---
apiVersion: v1
kind: Service
metadata:
name: svc-apple
spec:
selector:
app: apple
ports:
- port: 5678 # Default port for image
EOF
kubectl delete -f svc-apple.yaml
kubectl apply -f svc-apple.yaml
cat>svc-banana.yaml<<-'EOF'
apiVersion: v1
kind: Pod
metadata:
name: pod-banana
labels:
app: banana
spec:
containers:
- name: pod-banana
image: hashicorp/http-echo
args:
- "-text=banana"
---
apiVersion: v1
kind: Service
metadata:
name: svc-banana
spec:
selector:
app: banana
ports:
- port: 5678 # Default port for image
EOF
kubectl delete -f svc-banana.yaml
kubectl apply -f svc-banana.yaml
cat>ingress-example.yaml<<-'EOF'
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-example
annotations:
nginx.ingress.kubernetes.io/rewrite-target: "/"
spec:
ingressClassName: nginx
rules:
- host: foo.bar.com
http:
paths:
- path: /apple
pathType: Prefix
backend:
service:
name: svc-apple
port:
number: 5678
- path: /banana
pathType: Prefix
backend:
service:
name: svc-banana
port:
number: 5678
EOF
kubectl delete -f ingress-example.yaml
kubectl apply -f ingress-example.yaml
kubectl get ingress
NAME CLASS HOSTSADDRESS PORTS AGE
ingress-example nginx* 192.168.49.2 80 8s
kubectl describe ingress ingress-example
Name:ingress-example
Labels:<none>
Namespace:default
Address:192.168.49.2
IngressClass:nginx
Defaultbackend:<default>
Rules:
HostPathBackends
----------------
*
/applesvc-apple:5678(172.16.10.74:5678)
/bananasvc-banana:5678(172.16.10.75:5678)
Annotations:ingress.kubernetes.io/rewrite-target:/
Events:
TypeReasonAgeFromMessage
-------------------------
NormalSync57s(x2over64s)nginx-ingress-controllerScheduledforsync
kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.96.42.20 <none> 80:30691/TCP,443:31606/TCP 17m
ingress-nginx-controller-admission ClusterIP 10.103.187.67 <none> 443/TCP 17
# EXTERNAL-IP none 宿主机不能访问minikube集群,minikube仅学习用
# 修改/etc/hosts
#localhost name resolution is handled within DNS itself.
#127.0.0.1 localhost ::1 localhost
192.168.49.2 foo.bar.com
# 测试
curl http://foo.bar.com:30691/apple
curl http://192.168.49.2:30691/apple
curl http://192.168.49.2:30691/banana
# (/|$)(.*)表示2组匹配,
# 第一组表示/或者结束符,表示匹配 apple 后面要么是 /,要么直接是路径的结尾。
# 第二组表示"."匹配任意单个字符(包括字母、数字、符号等,除了换行符)。"*"表示前面的 . 可以出现零次或多次。
# (.*) 捕获了 /apple 或 /apple/ 后的所有内容。如果没有内容(即空字符串),也能匹配。
# 总结
# 匹配路径必须以 /apple 开头。
# 在 apple 之后:
# 如果是 / 或路径结束(由 (/|$) 匹配),继续匹配。
# 捕获 / 或空字符串。
# 捕获剩余路径的内容(.*)。
# foo.bar.com/apple/abc请求会被派发到svc-apple:5678/abc
# foo.bar.com/banana/bcd请求会被派发到svc-banana:5678/bcd
mkdir/etc/k8s
cd/etc/k8s
cat>ingress-example.yaml<<-'EOF'
apiVersion:networking.k8s.io/v1
kind:Ingress
metadata:
name:ingress-example
annotations:
#直接映射⾄根路径
ingress.kubernetes.io/rewrite-target:/$2
spec:
ingressClassName:nginx
rules:
- host:foo.bar.com
http:
paths:
- path:/apple(/|$)(.*)
pathType:Prefix
backend:
service:
name:svc-apple
port:
number:5678
- path:/banana(/|$)(.*)
pathType:Prefix
backend:
service:
name:svc-banana
port:
number:5678
EOF
kubectl delete -f ingress-example.yaml
kubectl apply -f ingress-example.yaml
Ingress与Ingress-controller如何结合的?
- IngressClass代表Ingress的类,ingressclass.kubernetes.io/is-default-class注解可以⽤来标明⼀个IngressClass应该被视为默认的Ingress类。当某个IngressClass资源将此注解设置为true时,没有指定类的新Ingress资源将被分配到此默认类。
- 参考安装nginx-Ingress-Controller的yaml文件
IngressClass.spec.controller指的是应该处理这个类的控制器的名称。
IngressClass.metadata.name指的是当前ingressClass定义的名字
Deployment.spec.template.spec.args
--controller-class:IngressClass.spec.controller值应与此处指定的值相同,以使该对象受到监视。
--ingress-class:与IngressClass.metadata.name相同,形成绑定关系,如果不写默认值为"nginx"
本质就是修改Ingress-nginx-controllerPod中的nginx.conf⽂件完成请求转发与路由
# Ingress配置文件指定了ingressClassName: nginx
# k8s找到对应的ingressClass
kubectl get ingressclass
NAME CONTROLLER PARAMETERS AGE
nginx k8s.io/ingress-nginx <none> 20h
kubectl describe ingressclass
Name: nginx
Labels: app.kubernetes.io/component=controller
app.kubernetes.io/instance=ingress-nginx
app.kubernetes.io/name=ingress-nginx
app.kubernetes.io/part-of=ingress-nginx
app.kubernetes.io/version=1.5.1
Annotations: <none>
Controller: k8s.io/ingress-nginx
Events: <none>
# 通过关键参数Name与Controller确定匹配的Deployment
kubectl get deployment -A
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
ingress-nginx ingress-nginx-controller 1/1 1 1 20h
kubectl describe deploy ingress-nginx -n ingress-nginx
curl https://manongbiji.oss-cn-beijing.aliyuncs.com/ittailkshow/k8s/download/ingress-nginx-1.5.1.yaml
...
apiVersion:apps/v1
kind:Deployment
metadata:
labels:
app.kubernetes.io/component:controller
app.kubernetes.io/instance:ingress-nginx
app.kubernetes.io/name:ingress-nginx
app.kubernetes.io/part-of:ingress-nginx
app.kubernetes.io/version:1.5.1
name:ingress-nginx-controller
namespace:ingress-nginx
spec:
minReadySeconds:0
revisionHistoryLimit:10
selector:
matchLabels:
app.kubernetes.io/component:controller
app.kubernetes.io/instance:ingress-nginx
app.kubernetes.io/name:ingress-nginx
template:
metadata:
labels:
app.kubernetes.io/component:controller
app.kubernetes.io/instance:ingress-nginx
app.kubernetes.io/name:ingress-nginx
spec:
containers:
-args:
-/nginx-ingress-controller
---election-id=ingress-nginx-leader
---controller-class=k8s.io/ingress-nginx
---ingress-class=nginx
---configmap=$(POD_NAMESPACE)/ingress-nginx-controller
---validating-webhook=:8443
---validating-webhook-certificate=/usr/local/certificates/cert
---validating-webhook-key=/usr/local/certificates/key
env:
...
---
apiVersion:networking.k8s.io/v1
kind:IngressClass
metadata:
labels:
app.kubernetes.io/component:controller
app.kubernetes.io/instance:ingress-nginx
app.kubernetes.io/name:ingress-nginx
app.kubernetes.io/part-of:ingress-nginx
app.kubernetes.io/version:1.5.1
name:nginx
spec:
controller:k8s.io/ingress-nginx
隔离机制之Namespaces命名空间,DNS
命名空间是⼀种在多个⽤户之间划分集群资源的⽅法(通过资源配额)。资源名称需要在命名空间内唯⼀,但不能跨命名空间。命名空间不能彼此嵌套,并且每个Kubernetes资源只能⾪属于某⼀个命名空间。基于names的作⽤域仅适⽤于命名空间的对象(Deployments、Services等),
不适⽤于群集对象(例如:storageClass、Nodes、PersistentVolumes等)
在在许多⽤户分布在多个团队或项⽬中的环境中使⽤。
不必使⽤多个命名空间来分隔略有不同的资源,例如同⼀软件的不同版本:正确的做法是使⽤标签(label)来区分同⼀命名空间内的资源。
注意:对于⽣产集群,请考虑不使⽤default命名空间。应当使⽤指定的命名空间进⾏资源分配。
四个内置命名空间
default:默认,以便⽤新集群,⽽⽆需先创建命名空间
kube-node-lease:节点租约命名空间,保存与每个节点关联的租约对象。节点租赁允许kubelet发送⼼跳,以便控制平⾯可以检测到节点故障
kube-public:可被所有客户端(包括未经身份验证的客户端)读取。如果某些资源应该在整个集群中公开可⻅和可读
kube-system:由Kubernetes系统创建的对象的命名空间
# 查看现有的命名空间
kubectl get namespace
NAMES TATUS AGE
default Active 11d
kube-node-lease Active 11d
kube-public Active 11d
kube-system Active 11d
# 为当前请求(命令)设置命名空间,--namespace与-n等价
kubectl run nginx--image=nginx--namespace=default
kubectl get pods -n kube-system
# 创建新命名空间
cat>newnamespace.yml<<-'EOF'
apiVersion:v1
kind:Namespace
metadata:
labels:
app.kubernetes.io/instance:ingress-nginx
app.kubernetes.io/name:ingress-nginx
name:ingress-nginx
EOF
kubectl apply -f newnamespace.yml
# 或者
kubectl create namespace my-namespace
命名空间and DNS
创建服务时,它会创建相应的DNS条⽬。如果容器只⽤<service-name>,它将解析为命名空间本地的服务。对于跨多个命名空间(例如开发,暂存和⽣产)使⽤相同的配置很有⽤。如果要跨越命名空间,则需要使⽤完限定名(FQDN)。
<service-name>.<namespace>.svc.cluster.local
例⼦
svc-apple.default.svc.cluster.local
svc-apple.dev.svc.cluster.local
# 哪些对象可以⽤命名空间切分
kubectl api-resources --namespaced=true
#哪些对象不可以⽤命名空间切分
kubectl api-resources --namespaced=false
StatefulSet(有状态集)与Deployment(⽆状态部署)区别、StatefulSet的⽆头服务Headless Services及作⽤,注意事项,更新策略
- StatefulSet是⽤来管理有状态应⽤的⼯作负载API对象。管理基于相同容器规约的⼀组Pod集合的部署和扩缩,并为这些Pod提供持久存储和持久标识符。为每个Pod维护永久不变的ID。不能相互替换:⽆论怎么调度,
- 如果希望使⽤存储卷为⼯作负载提供持久存储,可以⽤StatefulSet。尽管StatefulSet中的单个Pod仍可能出现故障,但持久的Pod标识符使得将现有卷与替换已失败Pod的新Pod相匹配变得更加容易。
- Deployment部署的⽆状态Pod,Name是随机产⽣的
- StatefulSet创建的有状态Pod,Pod是有序创建的
- StatefulSet对于需要满⾜以下⼀个或多个需求的应⽤程序很有价值:
稳定的、唯⼀的⽹络标识符。
稳定的、持久的存储。
有序的、优雅的部署和扩缩。
有序的、⾃动的滚动更新。
稳定是指Pod调度或重调度的过程是持久性的。如果应⽤程序不需要任何稳定的标识符或有序的部署、删除或扩缩,则应该使⽤由⼀组⽆状态的副本控制器提供的⼯作负载来部署应⽤程序,⽐如Deployment或者ReplicaSet
mkdir /etc/k8s
cat > ss-nginx.yaml <<-'EOF'
# Headless Service
apiVersion: v1
kind: Service
metadata:
name: hsvc-nginx
spec:
selector:
app: nginx
ports:
- port: 8000
clusterIP: None
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: ss-nginx
spec:
serviceName: hsvc-nginx
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: container-nginx
image: nginx:1.20.2-alpine
ports:
- containerPort: 80
EOF
kubectl delete -f ss-nginx.yaml
kubectl apply -f ss-nginx.yaml
kubectl get statefulset
NAME READY AGE
ss-nginx 2/2 33m
kubectl get pods
NAME READY STATUS RESTARTS AGE
ss-nginx-0 1/1 Running 0 107s
ss-nginx-1 1/1 Running 0 106s
- 不需要负载均衡、单独的ServiceIP。可以指定ClusterIP(spec.clusterIP)的值为"None"来创建HeadlessService。
- ⽆头Service可以与其他服务发现机制进⾏接⼝,⽽不必与Kubernetes的实现捆绑在⼀起。
- ⽆头Services不会分配ClusterIP,kube-proxy不会处理,平台也不会进⾏负载均衡和路由。DNS实现⾃动配置依赖于Service是否定义了选择算符。
- 定义了选择算符的⽆头服务,控制平⾯在API中创建EndpointSlice对象,并且修改DNS配置返回A或AAA条记录(IPv4、6地址),通过这个地址直接到达Service的后端Pod上。
# 跟上面声明一样,curl地址参考命名空间
kubectl exec --stdin --tty ss-nginx-0 -- sh
/# curl ss-nginx-1.hsvc-nginx.default.svc.cluster.local
<!DOCTYPEhtml> ...
# 因为ss-nginx-0与ss-nginx-1在同⼀命名空间下,因此后半部分可以省去的。如果需要访问别的命名空间下后缀必须加上
/# curl ss-nginx-1.hsvc-nginx
<!DOCTYPEhtml> ...
StatefulSet注意事项,限制
- 对于包含N个副本的StatefulSet,部署Pod时按顺序0..N-1创建,删除Pod时逆序N-1..0。
- 在将扩缩操作应⽤到Pod之前,前⾯所有Pod必须是Running和Ready状态。Pod终⽌之前,所有的继任者必须完全关闭。
- StatefulSet不应将pod.Spec.TerminationGracePeriodSeconds设置为0。不安全,解释参考强制删除StatefulSet Pod
terminationGracePeriodSeconds(int64)可选字段,表示Pod优雅终⽌时⻓(单位秒)。值必须是⾮负整数。0表示收到kill信号则⽴即停⽌。为nil将⽤默认宽限期。
是从Pod中运⾏的进程收到终⽌信号后,到进程被kill信号强制停⽌之前,Pod可以继续存在的时间。应该设置为⽐进程的预期清理时间更⻓。默认30 - 给定Pod的存储由PersistentVolume Provisioner基于storageclass来制备,或者由管理员预先制备。
- 为了保证数据安全。删除或者扩缩StatefulSet并不会删除它关联的存储卷。
- StatefulSet需要⽆头服务来负责Pod的⽹络标识。
- 为了实现StatefulSet中的Pod可以有序且体⾯地终⽌,可以在删除之前将StatefulSet缩容到0。
- 在默认Pod管理策略(OrderedReady)时使⽤滚动更新,可能进⼊需要⼈⼯⼲预才能修复的损坏状态。
apiVersion:apps/v1
kind:StatefulSet
metadata:
name:web
spec:
...
template:
metadata:
labels:
app:nginx
spec:
terminationGracePeriodSeconds:10
kubectl scale sts ss-nginx--replicas=0
kubectl delete sts ss-nginx
更新策略
- StatefulSet的.spec.updateStrategy字段可以配置和禁⽤掉⾃动滚动更新Pod的容器、标签、资源请求或限制、以及注解。
OnDelete:⼿动删除Pod让控制器创建新Pod
RollingUpdate(默认)控制器⾃动的滚动更新pod - StatefulSet的.spec.updateStrategy.rollingUpdate.partition的可以实现分区更新。
- 如果声明了⼀个分区,当StatefulSet的.spec.template被更新时,所有序号⼤于等于该分区序号的Pod都会被更新。⼩于则不更新,并且即使被删除也会依据旧版本重建。
- 如果StatefulSet的.spec.updateStrategy.rollingUpdate.partition⼤于它的.spec.replicas,则对它的.spec.template的更新将不会传递到它的Pod。
- 在阶段更新、执⾏⾦丝雀或执⾏分阶段上线时分区时有⽤
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
updateStrategy:
rollingUpdate:
partition: 2
利⽤Volume卷实现Pod数据持久化与资源共享,利用PV与PVC实现存储解耦,PV、PVC的绑定与访问模式,如何正确删除PV与PVC,利⽤StatefulSet为每⼀个Pod分配独⽴存储
Volume的作⽤
- 设置配置⽂件替代容器内的默认配置
- 将容器内产⽣的数据保存到容器外预防丢失
单独使用Volume的弊端
- 存储接口与实现严重耦合,并没有职责分离
- Volume卷并没有被K8S有效管理
- 数据迁移难
- 无法进行更细粒度的控制,如(大小、是否只能被单个Pod挂载、读写控制级别)
docker run --name some-nginx -v /some/content:/usr/share/nginx/html:ro -d nginx
# 或者docker file
FROM nginx
COPY static-html-directory /usr/share/nginx/htm1
# node0节点新建⽬录与HTML
rm -f /usr/local/share/logs/ng0
rm -f /usr/local/share/logs/ng1
rm -rf /usr/local/share/html
mkdir -p /usr/local/share/html
cat> /usr/local/share/html/test.html<<-'EOF'
<h1>I'm test page!</h1>
EOF
# master节点创建pod-nginx并挂载volume
cat > pod-nginx.yaml <<-'EOF'
apiVersion: v1
kind: Pod
metadata:
name: pod-nginx-0
spec:
# nodeName: node0
containers:
- name: ng0
image: nginx:1.20.2-alpine
ports:
- containerPort: 80
hostPort: 8000
volumeMounts:
- name: vol-html
mountPath: /usr/share/nginx/html
- name: vol-logs
mountPath: /var/log/nginx
volumes:
- name: vol-html
hostPath:
path: /usr/local/share/html
type: Directory
- name: vol-logs
hostPath:
path: /usr/local/share/logs/ng0
type: Directory
EOF
kubectl delete -f pod-nginx.yaml
kubectl apply -f pod-nginx.yaml
curl 192.168.49.2:8000/test.html
<h1>I'm test page!</h1>
利用PV(实现)与PVC(接口)实现存储解耦
- PersistentVolume是集群中的一块存储,由管理员配置或使用StorageClass动态配置。记录了存储的实现细节,无论其背后是NFS、iSCSI还是特定于云平台的存储系统。PV持久卷和普通的Volume都用卷插件实现。PV拥有独立于任何使用PV的Pod的生命周期。
- PersistentVolumeClaim(PVC)是用户对存储的请求。类似Pod。Pod消耗Node节点资源,PVC消耗PV资源。Pod请求特定级别的资源(CPU和内存)、PVC请求特定的存储空间尺寸和访问模式
- 在pvc绑定pv时根据存储大小和访问模式来绑定
pv的访问模式accessModes
ReadWriteOnce(RWO):Volume可以被⼀个Node以读写⽅式挂载。允许运⾏在同⼀Node上的多个Pod访问PV。
ReadOnlyMany(ROM):Volume可以被多个Node以只读⽅式挂载。
ReadWriteMany(RWM):Volume可以被多个Node同时读写
ReadWriteOncePod(RWOP):Volume可以被单个Pod以读写⽅式挂载。
如果你想确保整个集群中只有⼀个Pod可以读取或写⼊该PVC,请使⽤ReadWriteOncePod访问模式。只⽀持CSI卷以及需要Kubernetes1.22+
PV与PVC中AccessModes的区别
PV设置AccessModes代表该PV能够提供的存储能⼒
PVC设置AccessModes代表访问者(程序)需要PV提供的存储能⼒
PV中出现的AccessModes必须完全包含PVC的AccessModes才可以正常绑定,否则就会出现Pending阻塞
K8s⽤AccessModes匹配PersistentVolumeClaim和PersistentVolume。在某些场合下,Access Modes会限制PersistentVolume是否可以被挂载。AccessModes并不会在存储已经被挂载的情况下为其实施写保护。即使访问模式设置为ReadWriteOnce、ReadOnlyMany或ReadWriteMany,它们也不会对Volumes形成限制。例如,即使某个PV创建时设置为ReadOnlyMany,也⽆法保证该Volume是只读的。如果访问模式设置为ReadWriteOncePod,则Volume会被限制起来并且只能挂载到⼀个Pod上。
每个Volume同⼀时刻只能以⼀种访问模式挂载,即使Volume⽀持多种访问模式。例如,GCE PersistentDisk Volume可以被某节点以ReadWriteOnce模式挂载,或者被多个节点以ReadOnlyMany模式挂载,但不可以同时以两种模式挂载

# 主节点上
yum install -y nfs-utils rpcbind
systemctl enable nfs
rm -f /var/pv/mysql
mkdir -p /var/pv/mysql
chmod 755 /var/pv/mysql
cat > /etc/exports <<-'EOF'
/var/pv/mysql *(rw,async,no_root_squash)
EOF
systemctl restart rpcbind
systemctl enable rpcbind
systemctl restart nfs
systemctl enable nfs
showmount -e 192.168.1.184
Export list for 192.168.1.184:
/var/pv/mysql *
mkdir /etc/k8s
cat > /etc/k8s/pv-mysql.yaml <<-'EOF'
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-mysql
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
storageClassName: pv-mysql
persistentVolumeReclaimPolicy: Recycle
nfs:
path: /var/pv/mysql
server: 192.168.1.184
EOF
kubectl delete -f /etc/k8s/pv-mysql.yaml
kubectl apply -f /etc/k8s/pv-mysql.yaml
kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv-mysql 10Gi RWO Recycle Available pv-mysql 2m23s Filesystem
# 查看细节
kubectl describe pv pv-mysql
# 创建pvc
cat > /etc/k8s/pvc-mysql.yaml <<-'EOF'
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-mysql
namespace: default
spec:
storageClassName: pv-mysql
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
EOF
kubectl delete -f /etc/k8s/pvc-mysql.yaml
kubectl apply -f /etc/k8s/pvc-mysql.yaml
kubectl get pvc -o wide
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE
pvc-mysql Bound pv-mysql 10Gi RWO pv-mysql 10s Filesystem
kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv-mysql 10Gi RWO Recycle Bound default/pvc-mysql pv-mysql 10m
kubectl describe pvc pvc-mysql
Name: pvc-mysql
Namespace: default
StorageClass: pv-mysql
Status: Bound
Volume: pv-mysql
Labels: <none>
Annotations: pv.kubernetes.io/bind-completed: yes
pv.kubernetes.io/bound-by-controller: yes
Finalizers: [kubernetes.io/pvc-protection]
Capacity: 10Gi
Access Modes: RWO
VolumeMode: Filesystem
Used By: <none>
Events: <none>
# 创建mysql实例
cat > /etc/k8s/deploy-mysql.yml <<-'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-mysql
spec:
replicas: 1 # pod数量
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:8
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
volumeMounts:
- name: mysql-data
mountPath: /var/lib/mysql
volumes:
- name: mysql-data
persistentVolumeClaim:
claimName: pvc-mysql
EOF
kubectl delete -f /etc/k8s/deploy-mysql.yml
kubectl apply -f /etc/k8s/deploy-mysql.yml
kubectl get deploy -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deploy-mysql 1/1 1 1 3m58s mysql mysql:8 app=mysql
kubectl get pv -o wide
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
pv-mysql 10Gi RWO Recycle Bound default/pvc-mysql pv-mysql 27m Filesystem
kubectl get pvc -o wide
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE
pvc-mysql Bound pv-mysql 10Gi RWO pv-mysql 24m Filesystem
kubectl describe pvc pvc-mysql
Name: pvc-mysql
Namespace: default
StorageClass: pv-mysql
Status: Bound
Volume: pv-mysql
Labels: <none>
Annotations: pv.kubernetes.io/bind-completed: yes
pv.kubernetes.io/bound-by-controller: yes
Finalizers: [kubernetes.io/pvc-protection]
Capacity: 10Gi
Access Modes: RWO
VolumeMode: Filesystem
Used By: deploy-mysql-85dddbc486-cvd5r <=已绑定Pod
Events: <none>
# 工作节点
yum install -y nfs-utils
# 查看主节点挂载
showmount -e 192.168.1.184
正确删除PV与PVC
删除顺序deploy->pvc->pv
persistentVolumeReclaimPolicy-PV回收策略
Retain需⼿动删除。当PVC对象被删除时,PV仍保留数据,状态变为为"已释放(released)"且不能被其他PVC绑定,删除PV后数据仍保留
手动回收PV步骤
1.删除PV对象。与之相关的、位于外部基础设施中的存储资产(例如AWSEBS、阿⾥云OSS、AzureDisk等)在PV删除之后仍然存在
2.⼿动清除所关联的存储资产上的数据
3.⼿动删除所关联的存储资产
重⽤该存储资产可以基于存储资产的定义创建新PV对象Delete,删除时将PV对象从K8s中移除,同时会从外部基础设施(例如AWSEBS、阿⾥云OSS、AzureDisk等)中移除所关联的存储资产。动态PV会继承其StorageClass中设置的回收策略,默认Delete。管理员需要根据⽤户配置StorageClass;
Delete只删除存储设施上的Volume等信息,但不删除⽂件,因为NFS不⽀持Delete,所以Faild报错:“error getting deleter volume plugin for volume "pv-mysql":no deletable volume plugin matched”Recycle(回收)已被废弃。
如果下层的PV⽀持,会在PV上执⾏⼀些基本的删除命令(rm-rf/thevolume/*)操作删除数据,之后允许该PV⽤于新的PVC申领。
NFS和HostPath⽀持回收(Recycle)。AWSEBS、GCEPD、AzureDisk和Cinder卷都⽀持删除(Delete)。
Provisioner与StorageClass
StorageClass存储类:⾃动创建PV的机制,创建PV的模板。
Provisioner制备器:真正提供数据存储能⼒的应⽤程序,前⾯为了Node节点可以访问Master的NFS⽬录/var/pv/mysql,在每台Node上都安装NFS-Client提供⽹络传输功能,本质上NFSClient就是Provisioner,在⼤规模K8S集群下,通常Provisioner都是通过K8S以Pod形式⾃动部署的。
rm -rf /var/pv/mysql/*
mkdir /etc/k8s
cd /etc/k8s
cat > nfs-client-provisioner.yaml <<-'EOF'
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
namespace: default
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: default
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: default
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
namespace: default
labels:
app: nfs-client-provisioner
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: dyrnq/nfs-subdir-external-provisioner:v4.0.2
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner
- name: NFS_SERVER
value: 192.168.1.184
- name: NFS_PATH
value: /var/pv/mysql
volumes:
- name: nfs-client-root
nfs:
server: 192.168.1.184
path: /var/pv/mysql/
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-nfs-storage
annotations:
storageclass.kubernetes.io/is-default-class: "false"
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:
pathPattern: ""
archiveOnDelete: "false"
mountOptions:
- hard
- nfsvers=4
EOF
kubectl delete -f nfs-client-provisioner.yaml
kubectl apply -f nfs-client-provisioner.yaml
kubectl get po
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-54648b788b-hwpvx 1/1 Running 0 49s
kubectl get sc
NAME PROVISIONER RECLAIM
POLICY VOLUME BINDINGMODE ALLOWVOLUMEEXPANSION AGE
managed-nfs-storage k8s-sigs.io/nfs-subdir-external-provisioner Delete Immediate false 55s
# ⾃定义StorageClass后边不需要⼿动创建PV,在创建PVC时会⾃动根据StorageClass描述创建PV
cat > pvc-mysql.yaml <<-'EOF'
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvc-mysql
spec:
storageClassName: managed-nfs-storage
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Mi
EOF
kubectl delete deploy deploy-mysql
kubectl delete -f pvc-mysql.yaml
kubectl apply -f pvc-mysql.yaml
# 通过StorageClass可以在PVC创建时⾃动创建PV
kubectl get pvc
kubectl get pv
# 部署MySQL脚本Deployment不变
# 删除Deploy并不会对PV与PVC产⽣影响,动态产⽣的PV默认策略为Delete,会随着PVC删除⼀并被删除
kubectl delete pvc pvc-mysql
kubectl get pvc
No resources found in default namespace.
kubectl get pv
No resources found
利⽤StatefulSet为每⼀个Pod分配独⽴存储
rm -rf /var/mnt
mkdir -p /var/mnt
chmod 755 /var/mnt
cat > /etc/exports <<-'EOF'
/var/mnt *(rw,sync,no_root_squash)
EOF
systemctl restart rpcbind
systemctl restart nfs
rm -rf /var/mnt/*
mkdir /etc/k8s
cd /etc/k8s
kubectl delete -f nfs-client-provisioner.yaml
kubectl apply -f nfs-client-provisioner.yaml
rm -rf /var/mnt/*
cat > /etc/k8s/stateful-mysql.yml <<-'EOF'
# Headless Service
apiVersion: v1
kind: Service
metadata:
name: hsvc-mysql
spec:
selector:
app: mysql
ports:
- port: 3306
clusterIP: None
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: stateful-mysql
spec:
replicas: 3 # pod数量
selector:
matchLabels:
app: mysql
serviceName: hsvc-mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:8
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
volumeMounts:
- name: pvc-mysql
mountPath: /var/lib/mysql
volumeClaimTemplates: # 定义创建 PVC 使用的模板
- metadata:
name: pvc-mysql
annotations: # 指定 storageclass,确保 PVC 与 PV 自动创建
volume.beta.kubernetes.io/storage-class: managed-nfs-storage
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 512Mi
EOF
kubectl delete -f /etc/k8s/stateful-mysql.yml
kubectl apply -f /etc/k8s/stateful-mysql.yml
kubectl get po
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-5974ffbd47-q7n9s 1/1 Running 0 23m
stateful-mysql-0 1/1 Running 0 24s
stateful-mysql-1 1/1 Running 0 22s
stateful-mysql-2 1/1 Running 0 18s
kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
pvc-mysql Bound pv-mysql 10Gi RWO pv-mysql <unset> 3h45m
pvc-mysql-stateful-mysql-0 Bound pvc-6726794b-3060-4a53-85a9-d60d15c4f43d 512Mi RWX managed-nfs-storage <unset> 75s
pvc-mysql-stateful-mysql-1 Bound pvc-db82749c-5b2b-4d18-81d7-1326a3513cce 512Mi RWX managed-nfs-storage <unset> 71s
pvc-mysql-stateful-mysql-2 Bound pvc-b209d390-6d6f-4aa8-9b39-478eb2782c8d 512Mi RWX managed-nfs-storage <unset> 55s
# 删除Stateful并不会删除PVC与PV
kubectl delete -f /etc/k8s/stateful-mysql.yml
kubectl get pvc
ll /var/mnt
# ⼿动删除PVC后,PVC、PV、⽂件都被删除
kubectl delete pvc pvc-mysql-stateful-mysql-0
kubectl delete pvc pvc-mysql-stateful-mysql-1
kubectl delete pvc pvc-mysql-stateful-mysql-2
kubectl get pv
ll /var/mnt
⽂件存储、块存储、对象存储
文件存储:FTP、NFS服务器、Nas
基于⽂件的存储,数据会以单条信息的形式存储在⽂件夹中,访问该数据时要知道相应的查找路径。存储在⽂件中的数据会根据有限数量的元数据来进⾏整理和检索,元数据会告诉⽂件所在的确切位置
每个⽂档都会按照某种类型的逻辑层次结构来排放。适⽤于直接和⽹络附加存储系统的⼀种数据存储系统;⽂件存储⼏乎可以存储任何内容。如复杂⽂件,并且有助于⽤户快速导航
基于⽂件的存储系统必须通过添置更多系统来进⾏横向扩展,⽽不是通过增添更多容量来进⾏纵向扩展。
块存储:磁盘阵列,硬盘,SAN
是裸磁盘,挂载到QVM后不能被操作系统应⽤直接访问,需要格式化成⽂件系统(ext3、ext4、NTFS等)后才能被访问。优势是性能⾼、时延低,适合于OLTP、NoSQL数据库等IO。但是⽆法容量弹性扩展,单盘最⼤只能32TB,且对共享访问的⽀持有限,需要配合类Oracle RAC、WSFC Windows故障转移集群等集群管理软件才能共享访问。因此主要还是针对单点的⾼性能,低时延的存储产品
对象存储:分布式服务器(oss、s3)
基于对象的存储,扁平结构,⽂件被拆分成多个部分并散布在多个硬件间。数据会被分解为称为"对象"的离散单元,并保存在单个存储库中,⽽不是作为⽂件夹中的⽂件或服务器上的块来保存。
作为模块化单元来⼯作:每个卷都是⼀个⾃包含式存储库,均含有数据、允许在分布式系统上找到对象的唯⼀标识符以及描述数据的元数据。元数据包括年龄、隐私/安全信息和访问突发事件等详细信息。也可以⾮常详细,并且能存储与视频拍摄地点、所⽤相机和各个帧中特写的演员有关的信息。为了检索数据,存储操作系统会使⽤元数据和标识符更好地分配负载,并允许管理员应⽤策略来执⾏更强⼤的搜索。
对象存储需要HTTP应⽤编程接⼝(API),供⼤多数客户端(各种语⾔)使⽤。~经济⾼效:只需为已⽤内容付费。可以轻松扩展,因⽽是公共云存储首选。适⽤于静态数据的存储系统,其灵活性和扁平性使它可以通过扩展来存储极⼤量的数据。对象具有⾜够的信息供应⽤快速查找数据,并且擅⻓存储⾮结构化数据。
缺点。⽆法修改对象——必须⼀次性完整地写⼊对象;不能很好地与传统数据库搭配使⽤,因为编写对象很缓慢,编写应⽤以使⽤对象存储API并不像使⽤⽂件存储简单
块存储,最底层的存储,关注的是磁盘的基本存储单元块(Block),可以没有软件服务器。
⽂件存储(像NAS)和对象存储(S3、七⽜云),是软件层⾯的存储,底层也基于块存储。
⽂件存储和对象存储的区别在于,
组织⽂件的⽅式,⽂件存储是有⽬录树的、有标准属性的(权限、⽤户、读写)。对象存储是扁平的、没有⽬录的、附加属性是灵活的,
⼝协议也。对象存储接⼝主要以S3与Swift为代表,是简单的GET、PUT、DEL和其他扩展,⽂件存储以POSIX接⼝为主,以libcephfs为代表
ConfigMap、Secret配置管理,ConfigMap以⽂件形式挂载到Pod,ConfigMap应⽤⾄Pod环境变量,ConfigMap与Secret⽀持热部署,ConfigMap多环境配置,Secret对敏感信息进⾏存储
ConfigMap将配置数据(环境变量)和应⽤程序代码分开
⽤于配置在Pod中运⾏的容器的设置、作为数据卷挂载、⽤作符合相应ConfigMap中设置的参数的附加组件或运算符。
ConfigMap类型
FileSystem Object:挂载configmap,每个键将被创建为具有相应值作为内容的⽂件
Environment variable:要动态传递给容器的键和值对
Commandline Argument:更改容器命令⾏参数的默认值
注意事项
信息未加密。因此不存储机密信息
ConfigMap⽂件⼤⼩不应超过1MB。超过则考虑挂载存储卷或者使⽤独⽴的数据库或者⽂件服务。
ConfigMap对象名称是DNS⼦域名
ConfigMaps与Namespace有关,只有同⼀Namespace中的pod才能引⽤
ConfigMaps不能⽤于静态pod
# ⽅式1:利⽤YAML⽂件创建
cat > configmap_Dev.yaml<<-'EOF'
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
# property-like keys; each key maps to a simple value
player_initial_lives: "3"
ui_properties_file_name: "user-interface.properties"
# file-like keys
game.properties: |
enemy.types=aliens,monsters
player.maximum-lives=5
user-interface.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
EOF
kubectl apply -f configmap_Dev.yaml
# ⽅法2:从同⼀⽬录中的多个常规⽂件创建ConfigMap。忽略任何其他条⽬(例如⼦⽬录、符号链接、管道、设备等)。
kubectl create configmap myconfigmap --from-file [path/to/yaml/directory]
# ⽅法3:从⽂件创建
kubectl create configmap [configmap_Dev] --from-file [path/to/file] --from-file[path/to/file2]...
# ⽅法4:创建⽂字值
kubectl create configmap [configmap_Dev] --from-literal [key1]=[value1] --from-literal [key2]=[value2]
# ⽅法5:从⽣成器创建⼀个ConfigMap。然后应⽤于在Apiserver上创建对象
1.14+通过Kustomize管理对象:⾃定义K8s配置的⼯具。功能是configMapGenerator,从⽂件或⽂字⽣成ConfigMap。在⽬录内的customization.yaml中指定⽣成器。
apiVersion:kustomize.config.k8s.io/v1beta1
kind:Kustomization
namespace:my-namespace
configMapGenerator:
- name:my-map
files:
- data/file1.json
ConfigMap以⽂件形式挂载到Pod
# ⽅式⼀:YAML创建configMap
mkdir /etc/k8s
cd /etc/k8s
cat > cm-nginx.yaml <<-'EOF'
apiVersion: v1
kind: ConfigMap
metadata:
name: cm-nginx
data:
nginx.conf: |
# 文件内容
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
# tcp_nopush on;
keepalive_timeout 65;
# gzip on;
include /etc/nginx/conf.d/*.conf;
}
EOF
kubectl delete -f cm-nginx.yaml
kubectl apply -f cm-nginx.yaml
kubectl get cm
NAME DATA AGE
cm-nginx 1 8s
kube-root-ca.crt 1 57d
kubectl describe cm cm-nginx
# ⽅式⼆:指定⽂件创建
mkdir /etc/k8s/nginx
cd /etc/k8s/nginx
cat > nginx.conf <<-'EOF'
# 文件内容后面的内容
EOF
kubectl delete cm cm-nginx
kubectl create cm cm-nginx --from-file /etc/k8s/nginx/nginx.conf
# Pod以⽂件⽅式挂载ConfigMap
cat > deploy-nginx.yaml <<-'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.20.2-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts:
- name: vol-nginx
mountPath: /etc/nginx/nginx.conf
subPath: nginx.conf
volumes:
- name: vol-nginx
configMap:
name: cm-nginx
items:
- key: nginx.conf
path: nginx.conf
EOF
kubectl delete -f deploy-nginx.yaml
kubectl apply -f deploy-nginx.yaml
kubectl get po
NAME READY STATUS RESTARTS AGE
deploy-nginx-67f4f67655-xxvht 1/1 Running 0 8s
kubectl exec --stdin --tty deploy-nginx-67f4f67655-xxvht -- sh
# cat /etc/nginx/nginx.conf
# itlaoqi
user nginx;
worker_processes 1;
...
ConfigMap应⽤⾄Pod环境变量
# 创建ConfigMap
kubectl delete cm cm-mysql
kubectl create cm cm-mysql --from-literal=RANDOM_PASSWORD=yes
# 查看cm-mysql详细内容
kubectl describe cm cm-mysql
Name: cm-mysql
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
RANDOM_PASSWORD:
----
yes
BinaryData
====
# 部署MySQL节点,利⽤valueFrom.configMapKeyRef完成cm-mysql.RANDOM_PASSWORD与mysql容器MYSQL_RANDOM_ROOT_PASSWORD环境变量的绑定
mkdir /etc/k8s
cd /etc/k8s
cat > /etc/k8s/deploy-mysql.yml <<-'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-mysql
spec:
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:8
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3306
env:
- name: MYSQL_RANDOM_ROOT_PASSWORD
valueFrom:
configMapKeyRef:
name: cm-mysql
key: RANDOM_PASSWORD
EOF
kubectl delete -f /etc/k8s/deploy-mysql.yml
kubectl apply -f /etc/k8s/deploy-mysql.yml
验证是否随机⽣成了ROOT密码
kubectl get pods
NAME READY STATUS RESTARTS AGE
deploy-mysql-846dbcc654-c4w7s 1/1 Running 0 7s
kubectl logs deploy-mysql-846dbcc654-c4w7s | grep GENERATED
[Note] [Entrypoint]: GENERATED ROOT PASSWORD: RCqllQJmoBxf+X1i7+5gLHtutMxYCU2V
ConfigMap与Secret⽀持热部署
https://github.com/stakater/Reloader
重新加载策略
Reloader⽤于对资源执⾏滚动升级。
env-vars:当跟踪的configMap/secret更新时,将Reloader特定的环境变量附加到引⽤已更改configMap或secret拥有资源(例如Deployment,,StatefulSet等)的任何容器。可⽤参数指定--reload-strategy=env-vars。默认。
annotations:当跟踪configMap/secret更新时,将reloader.stakater.com/last-reloadedfrom在拥有的资源(例如Deployment,,StatefulSet等)上附加⼀个pod模板注释。在使⽤ArgoCD等资源同步⼯具时有⽤,因为它不会导致这些⼯具在重新加载资源后检测配置漂移
注意:由于附加的pod模板注释仅跟踪最后的重新加载源,因此该策略将重新加载任何被跟踪的资源,如果它configMap被secret删除并重新创建。可以⽤参数指定--reloadstrategy=annotations
# ⾃动全量监听
kind: Deployment
metadata:
annotations:
reloader.stakater.com/auto: "true"
spec:
template:
# 局部监听:
# 1.部署脚本增加reloader.stakater.com/search=true
kind: Deployment
metadata:
annotations:
reloader.stakater.com/search: "true"
spec:
template:
# 2.ConfigMap增加reloader.stakater.com/match=true
kind: ConfigMap
metadata:
annotations:
reloader.stakater.com/match: "true"
data:
key: value
# 局部热更新
kind: Deployment
metadata:
annotations:
configmap.reloader.stakater.com/reload: "foo-configmap"
# 可以写多个
# configmap.reloader.stakater.com/reload: "foo-configmap,bar-configmap,baz-configmap"
spec:
template:
# 案例使⽤
# 安装
kubectl apply -f https://raw.githubusercontent.com/stakater/Reloader/master/deployments/kubernetes/reloader.yaml
# 配置cm
mkdir /etc/k8s
cd /etc/k8s
cat > cm-nginx.yaml <<-'EOF'
apiVersion: v1
kind: ConfigMap
metadata:
name: cm-nginx
data:
nginx.conf: |
# v1.0
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}
EOF
kubectl delete -f cm-nginx.yaml
kubectl apply -f cm-nginx.yaml
cat > deploy-nginx.yaml <<-'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-nginx
annotations:
reloader.stakater.com/auto: "true"
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
volumeMounts:
- name: vol-nginx
mountPath: /etc/nginx/nginx.conf
subPath: nginx.conf
volumes:
- name: vol-nginx
configMap:
name: cm-nginx
items:
- key: nginx.conf
path: nginx.conf
EOF
kubectl delete -f deploy-nginx.yaml
kubectl apply -f deploy-nginx.yaml
# 修改配置⽂件后,重新加载
kubectl apply -f cm-nginx.yaml
# 此时PodName已发⽣变化,说明已经滚动
kubectl get pod
# 进⼊容器查看确认,发现配置已更新
kubectl exec --stdin --tty deploy-nginx-dbddd58c8-8cgwd -- sh
# cat /etc/nginx/nginx.conf
# v1.1
user nginx;
ConfigMap多环境配置
ConfigMap基于Namespace隔离,Pod只会加载当前Namespace的ConfigMap
kubectl create namespace dev
kubectl create namespace prod
kubectl create namespace test
# 创建Dev Namespace ConfigMap
开发环境Dev
mkdir /etc/k8s/dev
cd /etc/k8s/dev
cat > cm-nginx.yaml <<-'EOF'
apiVersion: v1
kind: ConfigMap
metadata:
name: cm-nginx
namespace: dev
...
EOF
kubectl delete -f cm-nginx.yaml
kubectl apply -f cm-nginx.yaml
# 在Dev namespace下部署
cat > deploy-nginx.yaml <<-'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-nginx
namespace: dev
...
EOF
kubectl delete -f deploy-nginx.yaml
kubectl apply -f deploy-nginx.yaml
# 读取到Dev下的cm-config信息
kubectl get pod -n dev
NAME READY STATUS RESTARTS AGE
deploy-nginx-546c9b98bb-fzlft 1/1 Running 0 45s
deploy-nginx-546c9b98bb-lbtb2 1/1 Running 0 45s
deploy-nginx-546c9b98bb-vmzf8 1/1 Running 0 45s
kubectl exec deploy-nginx-546c9b98bb-fzlft -n dev -- cat /etc/nginx/nginx.conf
# ENV: DEV
user nginx;
...
Secret对敏感信息进⾏存储
Secret⽤于存储和管理敏感数据例如密码、令牌OAuth tokens或密钥ssh keys的对象。⽤Secret则不需要在代码中包含机密数据
由于创建Secret独⽴于使⽤它们的Pod,因此在创建、查看和编辑Pod的⼯作流程中暴露Secret及其数据的⻛险⼩。K8s和在集群中运⾏的应⽤程序也可以对Secret采取额外的预防措施,如避免将机密数据写⼊⾮易失性存储
Secret用法:
- 创建Pod时指定Service Account⾃动使⽤该Secret
- 通过挂载该Secret到Pod来使⽤
- 在Docker镜像下载时使⽤,通过指定Pod的spc.ImagePullSecrets来引⽤
ConfigMap和Secret选择?
- 使⽤ConfigMap存储⾮敏感的配置信息
- 使⽤Secret存储敏感的配置信息
- 如果配置⽂件既包含敏感信息、⼜包含⾮敏感信息,选择Secret存储
Secret和ConfigMap对⽐
同:
- 存储数据都属于key-value键值对形式
- 属于某个特定的namespace
- 可以导出到环境变量
- 可以通过⽬录/⽂件形式挂载(⽀持挂载所有key和部分key)
异: - Secret可以被ServerAccount关联使⽤
- Secret可以存储Register的鉴权信息,⽤于ImagePullSecret参数中,⽤于拉取私有仓库的镜像
- Secret⽀持Base64编码
- Secret分为多种类型,ConfigMap不区分类型
- Secret⽂件存储在tmpfs⽂件系统中,Pod删除后Secret也会对应被删除
Secret类型
type字段或者kubectl命令⾏参数设置类型
| 内置类型 | ⽤法 |
|---|---|
| Opaque | ⽤户定义的任意数据 |
| kubernetes.io/service-account-token | 服务账号令牌 |
| kubernetes.io/dockercfg | ~/.dockercfg ⽂件的序列化形式 |
| kubernetes.io/dockerconfigjson | ~/.docker/config.json ⽂件的序列化形式 |
| kubernetes.io/basic-auth | ⽤于基本身份认证的凭据 |
| kubernetes.io/ssh-auth | ⽤于 SSH 身份认证的凭据 |
| kubernetes.io/tls | ⽤于 TLS 客户端或者服务器端的数据 |
| bootstrap.kubernetes.io/token | 启动引导令牌数据 |
K8s对Secret对象采取额外了预防措施。
存储安全
只有当挂载Secret的POD调度到具体节点上时,Secret才会被发送并存储到该节点上。但不会被写⼊磁盘,⽽是存储在tmpfs中。⼀旦POD被删除,Secret就被删除。
由于节点上的Secret数据存储在tmpfs卷中,因此只会存在于内存中⽽不会写⼊到节点上的磁盘。以避免通过数据恢复等⽅法获取到敏感信息.
访问安全
同⼀节点上可能有多个POD分别拥有单个或多个Secret。但Secret只对请求挂载的POD中的容器才可⻅。因此,POD不能访问另⼀个POD的Secret
使⽤Secret⻛险
API server的Secret数据以纯⽂本的⽅式存储在etcd中,因此:
管理员应该限制admin⽤户访问etcd
API server中的Secret数据位于etcd使⽤的磁盘上;管理员在不再使⽤时擦除/粉碎etcd使⽤的磁盘
如果Secret数据编码为base64的(JSON 或 YAML)⽂件,共享该⽂件或将其检⼊代码库,密码将会被泄露。Base64编码不是⼀种加密⽅式,是纯⽂本
应⽤程序在从卷中读取Secret后仍需要保护Secret值,例如不会意外记录或发送给不信任⽅
可以创建和使⽤Secret的POD⽤户也可以Secret 的值。即使API server策略不允许⽤户读取Secret对象,⽤户也可以运⾏暴露Secret的POD
Secret会在多个副本共享。默认情况下,etcd不能保证与SSL/TLS的对等通信,但管理员可以配置
任何节点的root⽤户都可以通过kubelet读取API server中的任何Secret
环境变量⽅式
mkdir /etc/k8s
cd /etc/k8s
cat > secret.yaml <<-'EOF'
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
stringData:
USERNAME: admin
data:
# 密码1f2d1e2e67df被base64后
PASSWORD: MWYyZDFlMmU2N2Rm
EOF
kubectl delete -f secret.yaml
kubectl apply -f secret.yaml
kubectl describe secret mysecret
Name: mysecret
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
PASSWORD: 12 bytes
USERNAME: 5 bytes
# 环境变量方式
cat > secret-test-pod.yaml <<-'EOF'
apiVersion: v1
kind: Pod
metadata:
name: secret-test-pod
spec:
containers:
- name: test-container
image: busybox:1.37.0
command: [ "/bin/sh", "-c", "env" ]
envFrom:
- secretRef:
name: mysecret
restartPolicy: Never
EOF
kubectl delete -f secret-test-pod.yaml
kubectl apply -f secret-test-pod.yaml
# Secret并不安全
kubectl get secret mysecret -o yaml
apiVersion: v1
data:
PASSWORD: MWYyZDFlMmU2N2Rm
USERNAME: YWRtaW4=
kind: Secret
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","data":{"PASSWORD":"MWYyZDFlMmU2N2Rm"},"kind":"Secret","metadata":{"annotations":{},"name":"mysecret","namespace":"default"},"stringData":{"USERNAME":"admin"},"type":"Opaque"}
creationTimestamp: "2023-02-18T08:09:17Z"
name: mysecret
namespace: default
resourceVersion: "902222"
uid: febed5f8-426c-4dd1-bea5-06728167d817
type: Opaque
# 存储到配置⽂件
# config.yml整个文件内容base64后
apiUrl: "https://my.api.com/api/v1"
username: admin
password: 1f2d1e2e67df
mkdir /etc/k8s
cd /etc/k8s
cat > secret.yaml <<-'EOF'
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
config.yaml: YXBpVXJsOiAiaHR0cHM6Ly9teS5hcGkuY29tL2FwaS92MSIKdXNlcm5hbWU6IGFkbWluCnBhc3N3b3JkOiAxZjJkMWUyZTY3ZGY=
EOF
kubectl delete -f secret.yaml
kubectl apply -f secret.yaml
# ⽂件⽅式挂载
cat > secret-test-pod.yaml <<-'EOF'
apiVersion: v1
kind: Pod
metadata:
name: secret-test-pod
spec:
containers:
- name: test-container
image: nginx
volumeMounts:
# name 必须与下⾯的卷名匹配
- name: secret-volume
mountPath: /etc/secret-volume
readOnly: true
volumes:
- name: secret-volume
secret:
secretName: mysecret
EOF
kubectl delete -f secret-test-pod.yaml
kubectl apply -f secret-test-pod.yaml
# 验证
kubectl exec secret-test-pod -- ls /etc/secret-volume
config.yaml
kubectl exec secret-test-pod -- cat /etc/secret-volume/config.yaml
apiUrl:...
⼀次性任务-Job,CronJob创建基于时隔重复调度的Job
Job会创建⼀个或多个Pod,并将继续重试Pod的执⾏,直到指定数量的Pod成功终⽌。随着Pod成功结束,Job跟踪记录成功完成的Pod个数。当数量达到指定的成功个数阈值时,任务Job结束。删除Job的操作会清除所创建的全部Pod。挂起Job的操作会删除Job的所有活跃Pod,直到Job被再次恢复执⾏
使用场景
1、⾮并⾏任务:只启⼀个pod,pod成功,job正常结束
2、并⾏任务同时指定成功个数
3、有⼯作队列的并⾏任务
4、创建⼀个Job对象以可靠的⽅式运⾏某Pod直到完成。当第⼀个Pod失败或者被删除(⽐如因为节点硬件失效或者重启)时启动新Pod
Job不是设计⽤来完成通信密集型的并⾏程序,⽀持并⾏地处理⼀组独⽴但相关的workitem,如发送邮件,渲染帧,转码⽂件和扫描NoSql数据库中的key
配置
- .spec.completions:完成该Job需要执⾏成功的Pod数.默认1
- .spec.parallelism:能够同时运⾏的Pod数
- .spec.backoffLimit:允许执⾏失败的Pod数,默认6,0不允许Pod执⾏失败。如果Pod是restartPolicy为Nerver,则失败后会创建新Pod,如果是OnFailed,则会重启Pod,只要Pod失败⼀次就计算⼀次,⽽不是等整个Pod失败后再计算⼀个。当失败的次数达到该限制时Job结束,所有正在运⾏的Pod都会被删除
- .spec.activeDeadlineSeconds:Job的超时时间,运⾏时间超出该限制则Job失败,所有运⾏中的Pod会被结束并删除。不指定则不会超时
CronJob创建基于时隔重复调度的Job
CronJob⽤于执⾏排期操作,例如备份、⽣成报告等。⽤Cron格式编写,并周期性地在给定的调度时间执⾏Job。
Cron时间表语法
- .spec.schedule字段 必需。遵循Cron语法:
任务延迟开始的最后期限 - .spec.startingDeadlineSeconds字段 可选。表示任务如果错过了调度时间,开始该任务的截⽌时间的秒数。过了截⽌时间就不会开始该任务(未来的任务仍在调度之中)。例如,如果你有⼀个每天运⾏两次的备份任务,你可能会允许它最多延迟8⼩时开始,但不能更晚,因为更晚的备份没有意义:宁愿等待下⼀次计划的运⾏。
对于错过已配置的最后期限的Job将其视为失败的任务。如果没有指定就没有最后期限。如果被设置将会计算从预期创建Job到当前时间的时间差。如果时间差⼤于该限制,则跳过此次执⾏。例如,设置为200则允许在实际调度之后最多200秒内创建Job
并发性规则
仅适⽤于相同CronJob创建的任务。如果有多个CronJob是允许并发执⾏的
.spec.concurrencyPolicy 可选。声明任务执⾏时发⽣重叠如何处理。
Allow(默认):允许并发任务执⾏。
Forbid:不允许并发任务执⾏;如果新任务的执⾏时间到了⽽⽼任务没有执⾏完,忽略新任务的执⾏。
Replace:如果新任务的执⾏时间到了⽽⽼任务没有执⾏完,⽤新任务替换当前正在运⾏的任务。
mkdir /etc/k8s
cd /etc/k8s
cat > job-echo.yaml <<-'EOF'
apiVersion: batch/v1
kind: Job
metadata:
name: job-echo
namespace: default
labels:
job-name: job-echo
spec:
suspend: true # Kubernetes 1.21+ 支持,true 代表挂起 Job,false代表job⽴即执⾏
ttlSecondsAfterFinished: 100 # Job在执⾏结束之后(状态为completed或Failed)⾃动清理。设置为0表示执⾏结束⽴即删除,不设置则不会清除,需要开启TTLAfterFinished特性
backoffLimit: 4 # 失败后重试次数
completions: 2 # 成功执行的 Pod 数量 为空默认和parallelism数值⼀样
parallelism: 2 # 并行执行任务的 Pod 数量,如果parallelism数值⼤于未完成任务数,只会创建未完成的数量;⽐如completions是4,并发是3,第⼀次会创建3个Pod执⾏任务,第⼆次只会创建⼀个Pod执⾏任务
template:
spec:
containers:
- name: echo
image: registry.cn-beijing.aliyuncs.com/dotbalo/busybox
imagePullPolicy: Always
command:
- echo
- "Hello, Job"
resources: {} # 保留空值,表示无特殊资源限制
restartPolicy: Never
EOF
kubectl delete -f job-echo.yaml
kubectl apply -f job-echo.yaml
# 查看状态
kubectl get job
NAME COMPLETIONS DURATION AGE
job-echo 0/2 8s
kubectl describe job job-echo
Name: job-echo
Namespace: default
Selector: controller-uid=4f03e419-d3a2-45c4-840f-c29f29a295ce
Labels: job-name=job-echo
Annotations: batch.kubernetes.io/job-tracking:
Parallelism: 2
Completions: 2
Completion Mode: NonIndexed
Pods Statuses: 0 Active (0 Ready) / 0 Succeeded / 0 Failed
Pod Template:
Labels: controller-uid=4f03e419-d3a2-45c4-840f-c29f29a295ce
job-name=job-echo
Containers:
echo:
Image: registry.cn-beijing.aliyuncs.com/dotbalo/busybox
Port: <none>
Host Port: <none>
Command:
echo
Hello, Job
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Suspended 23s job-controller Job suspended
# 激活运⾏job-echo
kubectl patch job/job-echo --type=strategic --patch '{"spec":{"suspend":false}}'
# 查看⼯作状态
kubectl describe job job-echo
..Job completed
kubectl get job
NAME COMPLETIONS DURATION AGE
job-echo 2/2 4s 2m9s
kubectl get po
NAME READY STATUS RESTARTS AGE
job-echo-tm4wg 0/1 Completed 0 92s
job-echo-zzw82 0/1 Completed 0 92s
kubectl logs job-echo-kxnkm
Hello, Job
mkdir /etc/k8s
cd /etc/k8s
cat > job-echo.yaml <<-'EOF'
apiVersion: batch/v1
kind: CronJob
metadata:
name: job-echo
spec:
schedule: "* * * * *" # 每分钟运行一次
jobTemplate:
spec:
template:
spec:
containers:
- name: job-echo
image: registry.cn-beijing.aliyuncs.com/dotbalo/busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure # 失败时重启容器
EOF
kubectl delete -f job-echo.yaml
kubectl apply -f job-echo.yaml
kubectl get jobs --watch
NAME COMPLETIONS DURATION AGE
job-echo-27948099 0/1 0s
job-echo-27948099 0/1 0s 0s
job-echo-27948099 0/1 3s 3s
job-echo-27948099 1/1 3s 3s
job-echo-27948100 0/1 0s
job-echo-27948100 0/1 0s 0s
job-echo-27948100 0/1 3s 3s
job-echo-27948100 1/1 3s 3s
job-echo-27948101 0/1 0s
job-echo-27948101 0/1 0s 0s
job-echo-27948101 0/1 3s 3s
job-echo-27948101 1/1 3s 3s
kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
job-echo * * * * * False 0 6s 3m45s
基于KS实现⾦丝雀发布
⾦丝雀发布/灰度发布(Canaryreleas)是⼀种降低在⽣产中引⼊新软件版本的⻛险的技术,将更改推⼴到整个基础架构并使其可供所有⼈使⽤之前,缓慢地将更改推⼴到⼀⼩部分⽤户。
基于K8S业界中最佳实践
通过节点亲和性特性在对应节点⾃动发布,控制不同版本的分布
如何控制动态扩容
kubectl label nodes node1 dtype=secondary
kubectl scale deploy deploy-nginx-v1 --replicas=15
kubectl scale deploy deploy-nginx-v2 --replicas=12
如何实现访问可控
按⽐例实现流量分发:nginx.ingress.kubernetes.io/canary-weight:"10"
流量稳定投递到V1/V2Pod:设置IPVS模式为sh
⾦丝雀发布实战
# 安装ingress-nginx-controller,参考上面
# 查看安装结果,获取对外暴露的端⼝号
kubectl get all -n ingress-nginx
minikube service ingress-nginx-controller -n ingress-nginx --url
# 部署nginx-v1
mkdir /etc/k8s
cd /etc/k8s
cat > deploy-openresty-v1.yaml <<-'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-v1
spec:
replicas: 1
selector:
matchLabels:
app: nginx
version: v1
template:
metadata:
labels:
app: nginx
version: v1
spec:
containers:
- name: nginx
image: "openresty/openresty:centos"
ports:
- name: http
protocol: TCP
containerPort: 80
volumeMounts:
- mountPath: /usr/local/openresty/nginx/conf/nginx.conf
name: config
subPath: nginx.conf
volumes:
- name: config
configMap:
name: nginx-v1
---
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app: nginx
version: v1
name: nginx-v1
data:
nginx.conf: |-
worker_processes 1;
events {
accept_mutex on;
multi_accept on;
use epoll;
worker_connections 1024;
}
http {
ignore_invalid_headers off;
server {
listen 80;
location / {
access_by_lua 'local header_str = ngx.say("nginx-v1")';
}
}
}
---
apiVersion: v1
kind: Service
metadata:
name: nginx-v1
spec:
type: ClusterIP
ports:
- port: 80
protocol: TCP
name: http
selector:
app: nginx
version: v1
EOF
kubectl delete -f deploy-openresty-v1.yaml
kubectl apply -f deploy-openresty-v1.yaml
# 验证
kubectl get po
# 部署nginx-v2
cat > deploy-openresty-v2.yaml <<-'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-v2
spec:
replicas: 1
selector:
matchLabels:
app: nginx
version: v2
template:
metadata:
labels:
app: nginx
version: v2
spec:
containers:
- name: nginx
image: "openresty/openresty:centos"
imagePullPolicy: IfNotPresent
ports:
- name: http
protocol: TCP
containerPort: 80
volumeMounts:
- name: config
mountPath: /usr/local/openresty/nginx/conf/nginx.conf
subPath: nginx.conf
volumes:
- name: config
configMap:
name: nginx-v2
---
apiVersion: v1
kind: ConfigMap
metadata:
name: nginx-v2
labels:
app: nginx
version: v2
data:
nginx.conf: |-
worker_processes 1;
events {
accept_mutex on;
multi_accept on;
use epoll;
worker_connections 1024;
}
http {
ignore_invalid_headers off;
server {
listen 80;
location / {
access_by_lua 'ngx.say("nginx-v2")';
}
}
}
---
apiVersion: v1
kind: Service
metadata:
name: nginx-v2
spec:
type: ClusterIP
ports:
- port: 80
protocol: TCP
targetPort: 80
name: http
selector:
app: nginx
version: v2
EOF
kubectl delete -f deploy-openresty-v2.yaml
kubectl apply -f deploy-openresty-v2.yaml
# 验证
kubectl get po
NAME READY STATUS RESTARTS AGE
nginx-v1-6c5f8cc7b8-6r447 1/1 Running 0 3m22s
nginx-v2-669cc8cbd6-8k2n8 1/1 Running 0 4s
# 部署ingress-nginx-v1
cat > ingress-nginx-v1.yaml <<-'EOF'
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx
annotations:
ingress.kubernetes.io/rewrite-target: /
spec:
ingressClassName: nginx
rules:
- host: foo.itlaoqi.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: nginx-v1
port:
number: 80
EOF
kubectl delete -f ingress-nginx-v1.yaml
kubectl apply -f ingress-nginx-v1.yaml
kubectl get ingress
# 部署ingress-nginx-v2
cat > ingress-nginx-v2.yaml <<-'EOF'
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx-canary
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
nginx.ingress.kubernetes.io/canary: "true" # 开启灰度发布
nginx.ingress.kubernetes.io/canary-by-header: "Region" # 如果请求头包含 Region 属性,则路由到 v2
nginx.ingress.kubernetes.io/canary-weight: "10" # v2 版本的权重
spec:
ingressClassName: nginx
rules:
- host: foo.itlaoqi.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: nginx-v2
port:
number: 80
EOF
kubectl delete -f ingress-nginx-v2.yaml
kubectl apply -f ingress-nginx-v2.yaml
kubectl get ingress
# 配置hosts⽂件
cat >> /etc/hosts <<-'EOF'
192.168.49.2 foo.itlaoqi.com
EOF
# 测试灰度发布过程
minikube service ingress-nginx-controller -n ingress-nginx --url
# 10%流量⾛v2
while sleep 0.2;do curl http://foo.itlaoqi.com:31483&& echo "";done
# 强制⾛v2
while sleep 0.2;do curl -H 'Region:always' http://foo.itlaoqi.com:31483&& echo "";done
Portainer的安装和使用
轻量级的容器管理工具,管理Docker和Kubernetes,
它提供了一个Web界面来方便我们管理容器,
官方网址: https://www.portainer.io/
安装Portainer
创建一个名字叫做portainer的虚拟机
multipass launch --name portainer --cpus 2 --memory 8G --disk 10G
在master节点上安装portainer,并将其暴露在NodePort 30777上
kubectl apply -n portainer -f https://downloads.portainer.io/ce2-19/portainer.yaml
或者用Helm安装Portainer
helm upgrade --install --create-namespace -n portainer portainer portainer/portainer --set tls.force=true
然后直接访问 https://localhost:30779/ 或者 http://localhost:30777/ 就可以了,
Helm的安装和使用
Helm是一个K8s的包管理工具
提供命令行工具管理Kubernetes的应用
官方网址: https://helm.sh/
安装Helm
# 使用包管理器安装:
curl https://baltocdn.com/helm/signing.asc | gpg --dearmor | sudo tee /usr/share/keyrings/helm.gpg > /dev/null
sudo apt-get install apt-transport-https --yes
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/helm.gpg] https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helm
# Linux(CentOS/Fedora)
sudo dnf install helm
# Linux(Snap)
sudo snap install helm --classic
# Linux(FreeBSD)
pkg install helm
# 使用脚本安装
$ curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
$ chmod 700 get_helm.sh
$ ./get_helm.sh
或者
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
containerport、port、targetport、nodeport
containerport:容器pod内监听程序端口
port:service对集群内部暴露的端口,其他pod通过这个端口访问service
targetport:Service 访问 Pod 时映射到的 containerPort
nodeport:在每个 Node 上分配的端口(范围 30000-32767),用于从集群外部访问 Service,它会转发到 targetPort。