MySQL问题解决
MySQL问题定位/死锁排查步骤√/CPU/内存100% √
show processlist查看session情况:找出有长时间运行的sql或处于Sleep状态的连接是否过多
开启并查看慢查询日志找慢SQL:看看执行计划是否使用索引,数据量是否太大
my.cnf配置或者--log-slow-queries[=file_name]选项启动
slow_query_log = ON
slow_query_log_file = /usr/local/mysql/data/slowselect.log
long_query_time = 1 #超过1秒则为慢查询
# 检查慢查日志是否开启/阈值(默认10s)/位置
show variables like 'slow_query_log/long_query_time/slow_query_log_file';
# 检查慢查日志开启/位置/阈值
set slow_query_log='ON';
set long_query_time = 2;
set slow_query_log_file=' /usr/share/mysql/sql_log/mysql-slow.log';
# 查看慢查询日志。
shell> more localhost-slow.log
# 慢查询日志存储格式
# Time: 180526 1:06:54 查询执行时间
# User@Host: root[root] @ localhost [] Id:4 执行sql的主机信息
# Query_time:0.000401 SQL查询时间
# Lock_time:0.000105 锁定时间
# Rows_sent:2 发送行数
# Rows_examined:2 扫描行数。行数越少,访问磁盘数据的次数越少,消耗CPU资源越少
# SET timestamp=1527268014; SQL执行时间
# select * from staff; SQL的执行内容
查看innodb引擎状态:show engine innodb status;
LATESTDETECTED DEADLOCK记录最后的死锁信息,TRANSACTION事务信息,引发死锁的SQL语句,事务已经获得的锁,正在等待什么锁,以及被回滚的事务等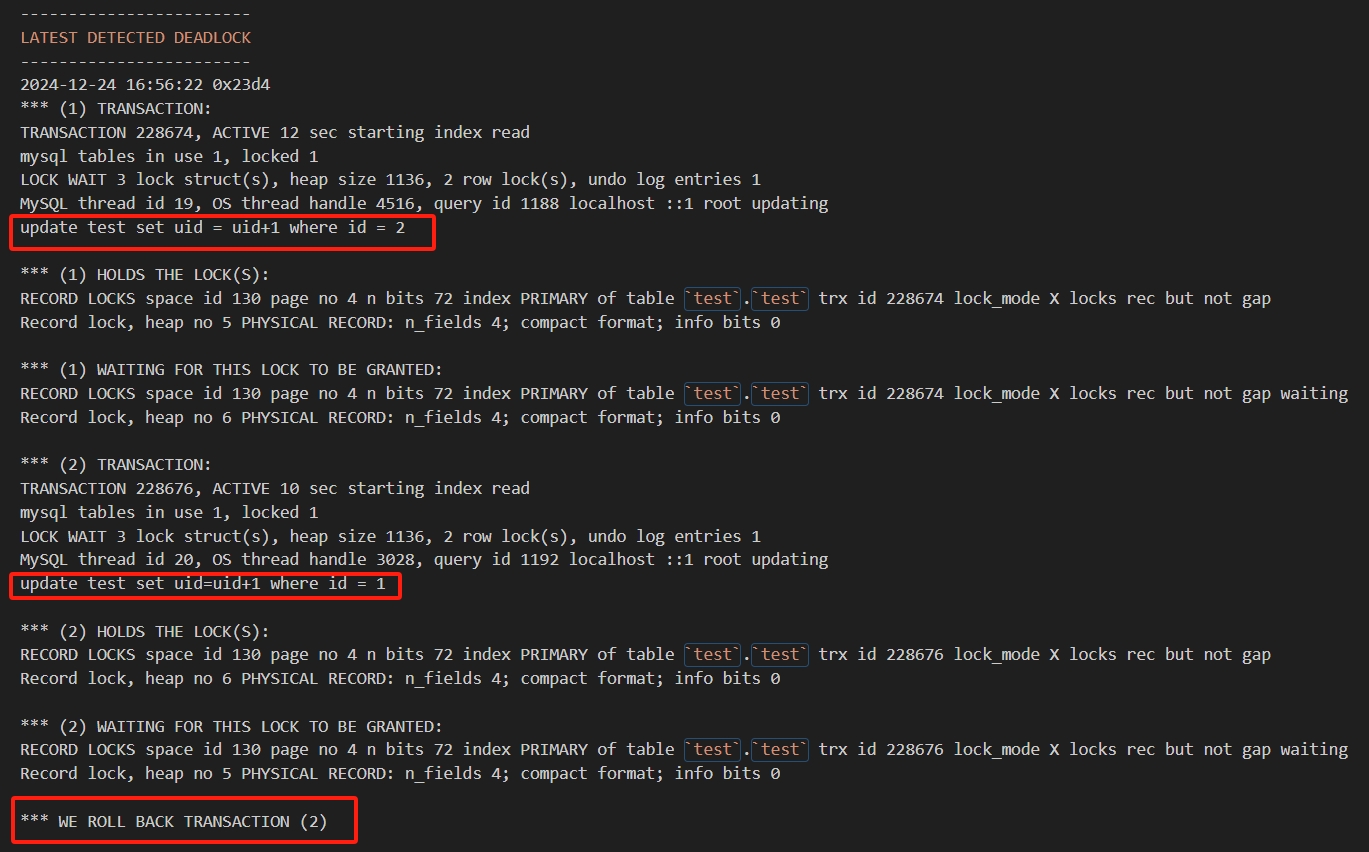
查询performance_schema和information_schema
-- 查询慢SQL,SQL_TEXT和DIGET_TEXT包含SQL
SELECT * FROM performance_schema.events_statements_current WHERE TIMER_WAIT > 1000000000;
-- 查询等待锁的session,PROCESSLIST_INFO字段包含SQL
SELECT t.THREAD_ID, t.PROCESSLIST_ID, t.PROCESSLIST_INFO,
l.OBJECT_SCHEMA, l.OBJECT_NAME, l.LOCK_TYPE, l.LOCK_MODE, l.LOCK_STATUS
FROM performance_schema.data_locks l
JOIN performance_schema.threads t ON l.THREAD_ID = t.THREAD_ID;


定位问题:找出死锁SQL或者慢SQL
紧急解决:kill掉线程,观察cpu使用率是否下降
分析问题:分析日志,sql加锁情况
重现问题:模拟并重现死锁或者慢SQL
得出解决方案:加索引、sql优化、改内存参数,重跑SQL或者客户端重试
MySQL死锁?√产生原因√例子√解决方案√
事务A等待事务B释放id=2的行锁,事务B等待事务A释放id=1的行锁。事务AB在互相等待对方的资源释放,进入死锁状态
| 事务A | 事务B |
|---|---|
| begin;update t set k=k+1 where id = 1; | begin; |
| update t set k=k+1 where id = 2; | |
| update t set k=k+1 where id = 2; | |
| update t set k=k+1 where id = 1; |
可重复读隔离级别下两个事务同时对相同条件记录用SELECT...FOR UPDATE加排他锁,没有符合条件记录情况下都会加锁成功。如果两个线程都发现记录不存在并插入一条新记录会出现死锁
MyISAM表锁不会出现死锁,因为一次获得所需的全部锁,要么全部满足,要么等待
~可能,因为InnoDB锁是逐步获得的,死锁检测到后会使一个事务释放锁并回滚。
在涉及外部锁或表锁的情况下不能完全检测到死锁,在高并发情况下,如果大量事务因无法获得所需的锁而挂起,会占用大量资源,造成严重性能问题,甚至拖跨数据库
遵循一致的访问顺序:确保所有事务以相同的顺序访问相同资源。减少死锁的可能性
事务尽可能短:减少事务持有锁的时间、锁冲突和死锁的可能性
使用合适的索引:减少表扫描和行锁的数量。优化查询性能,减少锁竞争
选择合适的锁:SQL加where条件用行级锁。更新记录用排他锁,而先用共享锁,再用排他锁时,其他事务可能获得了相同记录的共享锁造成锁冲突甚至死锁
设置主动死锁检测innodb_deadlock_detect为on(默认on) 对新线程申请锁判断会不会导致死锁,需要消耗大量CPU资源
设置合理的等待超时时间innodb_lock_wait_timeout(默认50s) :避免长时间等待锁及时中断可能的死锁。太短会误伤
定期监控和分析锁等待情况:找出潜在的死锁风险并优化,如SHOW ENGINE INNODB STATUS
程序捕获并处理死锁异常并重试:确保事务在死锁后重新执行
怎么解决热点行更新导致的性能问题呢?控制并发度,减少死锁检测工作
中间件
修改mysql:相同行的更新进入引擎前排队。
将一行改成逻辑上的多行来减少锁冲突。账户可以考虑放在多条记录上,账户总额等于10个记录值的总和。
每次给影院账户加金额时,随机选一条记录来加。锁冲突概率变成原来的1/10,账户余额减少时要考虑一部分行记录变成0的情况
SQL优化√SQL走索引依然慢原因?优化?√
开启慢查询日志√
定位慢SQL:mysqldumpslow分析慢查询日志,show processlist查看运行中的线程,state包括线程的状态、是否锁表、SQL执行情况。服务监控和告警:业务代码监控慢SQL,字节码插桩、连接池扩展、ORM框架过程√
mysqldumpslow --help
-s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time
ar: average rows sent
at: average query time
c: count
l: lock time
r: rows sent
t: query time
-r reverse the sort order (largest last instead of first)
-t NUM just show the top n queries
-a don't abstract all numbers to N and strings to 'S'
-n NUM abstract numbers with at least n digits within names
-g PATTERN grep: only consider stmts that include this string
-h HOSTNAME hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using mysql.server startup script)
-l don't subtract lock time from total time
## 锁定时间最长的前10条
mysqldumpslow -s l -t 10 /var/lib/mysql/mysql-slow.log
## 返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 mysql_slow.log
## 访问次数最多的10个SQL
mysqldumpslow -s c -t 10 mysql_slow.log
## 按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g “left join” mysql_slow.log
查看sql执行计划explain xxx√
- id:序列号,select子句或操作表的执行顺序。id值大先执行,值相同时由上而下,为null时表示结果集
- select_type:查询类型
SIMPLE:查询中不包含子查询、UNION、表连接
PRIMARY:查询中包含子查询、union时最外层的查询
SUBQUERY:SELECT或WHERE中包含子查询
DERIVED:FROM中包含子查询被标记为DRIVED
UNION:UNION中的第二个或者后面的查询,
dependent union:union或union all语句,受到外部查询的影响
dependent subquery:与dependent union类似,表示subquery查询~
union result:包含union的结果集,在union和union all语句中,不参与查询,所以id字段为null
UNION RESULT: 从union表获取结果的select - table:访问的表。null表示不操作表,
<derived N>/<union M,N>表示id为N/M,N的union结果集 - type列:表示关联或访问类型,速度如下,优化到ref级别
system:只有一行,速度快
const:查询时命中主键、唯一索引或被连接部分是一个常量值。扫描效率高,返回数据量少,速度快
eq_ref:多表连接时命中主键或唯一索引
ref:多表连接中使用普通索引
ref_or_null:与ref类似,增加了null值的比较
fulltext:全文索引,优先于普通索引
index_merge:索引合并优化,用了多个索引。最后取交集或者并集,and,or条件
unique_subquery:用于where中的in子查询返回唯一值
index_subquery:用于where中的in子查询可能返回重复值
range:针对索引字段给定范围查询。如bettween...and、<、>、<=、in等
index:扫描整个索引表,从索引中读取数据
ALL:全表扫描 - possible_keys:可能用到的索引
- key:真正用的索引,为null则没有用索引
- key_len:使用的索引最大长度,在不损失精确度的情况下越短越好
- ref:显示使用的索引列,const用常数等值查询,连接查询时被驱动表的显示驱动表的关联字段,条件使用表达式、函数或者条件列发生内部隐式转换时可能显示fun,NULL表示没有用索引
- rows:估算读取的行数,越少越好
- Extra:额外信息
distinct:select中用了distinc
no tables used:不带from的查询或From dual查询、用not in形式子查询或not exists的连接查询(反连接)。连接查询先查内表再查外表,反连接相反
Using filesort:用外部的索引排序(文件排序)。不按照索引顺序读取
Using temporary:用临时表保存中间结果。order by、group by
Using index:用覆盖索引避免回表。
using where:用where条件过滤。没有用索引覆盖
using join buffer:使连接缓存,join次数多可能会出现
impossible where:where子句值总是false。不能获取任何数据
using intersect/union:用and/or条件时,表示从处理结果获取交集
using sort_union和using sort_intersection:用and和or查询信息量大时,先查询主键后排序。合并后才能读取记录并返回。
firstmatch(tb_name):含有in()类型的子查询。内表的数据量大可能出现 - filtered:存储引擎返回数据在server层过滤后,剩下满足查询的记录数量的百分比
优化慢SQL?√
- 减少请求列(select *)、请求行(limit,where)
- 删除数据时分多次:数据量大时会一次性锁住很多数据、产生大量undo日志、阻塞其他查询
- 优先where过滤。而不是having过滤
- 分页(limit)优化(数据量大优化)
-- 延迟关联:先通过where条件提取主键再与原数据表关联
select a.* from table a,
(select id from table where type = 2 order by id asc limit 100000,10 ) b
where a.id = b.id
-- 书签方式:记住上次查询结果的最后一行的某个值,下次查询从这个值开始,避免扫描不需要的行
SELECT id, name FROM users
WHERE id > last_max_id -- 上一页最后一行的ID
ORDER BY id LIMIT 20;
- 索引优化:合理地设计和避免索引失效场景
临时添加/修改/删除索引:假设一主一备。1.备库关闭binlog:set sql_log_bin=off,执行alter table语句加索引,2.主备切换,3.原主库关闭binlog:set sql_log_bin=off,执行alter table语句加索引
gh-ost方案
在线修改SQL:MySQL5.7+安装Query Rewrite Plugin:insert into query_rewrite.rewrite_rules(pattern, replacement, pattern_database) values ("旧SQL", "新SQL", "db1");call query_rewrite.flush_rewrite_rules();
强制索引select * from t force index(a) where a=xxx; - JOIN优化
优化子查询:尽量用Join替代子查询,因为子查询是嵌套查询,会新创建临时表,临时表创建与销毁会占用系统资源和花费时间
关联查询时小表驱动大表:因为关联时会遍历驱动表,再连接被驱动表
子查询尽量不要放在被驱动表,有可能使用不到索引
可将子查询设置为驱动表,因为驱动表的type是all,而子查询返回的结果表没有索引也是all
适当增加冗余字段;减少连表查询,空间换时间。
避免用JOIN关联太多的表:阿里Java开发手册规定不超过三张表,降低查询的速度;join buffer占用更多内存。可以同步到ES中查询 - 排序优化:有两种方式生成有序结果:对结果集排序;按照索引顺序扫描结果自然有序。但如果索引不能覆盖查询所需列则需要回表,这个读操作是随机IO,通常会比顺序全表扫描慢。因此最好用同一个索引满足排序和查找行。
当索引的列顺序和ORDERBY子句的顺序完全一致,并且所有列的排序方向都一样时,才能用索引对结果排序 - UNION优化
条件下推:处理union先将查询结果填充到临时表中再查询,因此无法利用索引:将where、limit等子句下推到union子查询中
除非确实需要服务器去重,一定要使用unionall,会给临时表加distinct导致唯一性检查,代价高 - 清表要用truncate
- 数据类型最小可用、varchar 长度最小可用
- exists 和in 的取舍
- 尽量批量操作
- char 和 varchar 的抉择
- 多表关联控制量
- 函数在等号右侧
- 善用 straight_join:同inner join类似,但能让左边的表来驱动右边的表
- like 百分号向右
命中索引还要结合explain中的rows扫描行数
扫描行数过多可能是全表扫描,如果删除数据造成空洞太多可以定期用ANALYZE分析表减少空洞
为什么使用索引会加快查询?√如何设计索引?√索引不适合哪些场景呢?√索引哪些情况下会失效呢?√索引是不是越多越好?√
减少磁盘I/O操作:索引能快速定位数据再磁盘的位置,避免全表扫描,减少了磁盘I/O操作次数。
优化查询时间复杂度:全表扫描的时间复杂度是O(n),使用索引后时间复杂度为O(logN)
选择合适的列做索引:连接条件(ON)、查询条件(WHERE子句)、分组条件(GROUPBY子句)、排序条件(ORDERBY子句)、Using字句
避免过多的索引(索引的功能相同)
利用覆盖索引
适当使用前缀索引,降低索引的空间占用,提高索引查询效率。但无法做order by和group by操作,也无法作为覆盖索引
正确使用联合索引,注意最左匹配原则。
数据量少的表
更新频繁的字段
区分度低的字段(如性别)
无序字段(UUID),会造成叶子节点频繁分裂,磁盘碎片化
索引列用函数或表达式
索引列运算(如,+、-、*、/),
索引列用(!=或<>,notin)。!=、<>对主键和唯一索引字段走索引,对普通索引字段不走索引。改成or
like通配符(%xxx或_xx)
or查询条件中有一个不用索引。用union all代替
优化器估计全表扫描比用索引快
联合索引不满足最左前缀原则时
字符串类型字段查询时加引号,否则隐式类型转换相当于函数运算。查看数据类型转换系统默认规则:select "2" > 1 =>1表示“将字符串转成数字”,0相反
索引列用isnull,isnotnull
连接查询关联字段编码格式不一样,相当于函数运算
对连续区间用between就不用in。子查询用exists代替in
order by:索引范围查询,复合条件排序的desc、asc不一致
不是。
索引占用磁盘空间
降低更新表的速度:更新表INSERT、UPDATE、DELETE时,所有的索引都需要被更新。
维护索引文件需要成本;还会导致页分裂,IO次数增多。
单表索引不超过5个
MySQL调优
表设计,单行数据量大小尽可能小,确保每行数据尽可能小,因为一次性加载16KB内存数据页,一次I/O,B+树每个节点都是一个内存页的大小,tinityint表示男女
索引设计,主键索引,辅助索引,覆盖索引,select * 尽量避免走不了辅助索引,覆盖索引,执行计划判断索引是否生效
数据量增长,分区
mysql表垂直拆分和水平拆分,分表关联,一致性hash水平拆分
冷热备份