Redis
.1. Redis与MySQL区别?QPS?为什么快?I/O多路复用?实现方式?单线程模型?
数据存储在内存中的键值对NoSQL 数据库。读写性能高,常用作缓存中间件
数据存储在硬盘中的开源的关系型数据库管理系统,用于需要事务支持和复杂查询的场景
数万到几十万
Queries Per Second每秒查询率 受CPU、内存、命令类型等因素影响
基准测试命令:redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000(-c:并发连接数,-n:请求总数)
数据存储在内存,访问速度比磁盘快
单线程模型,避免线程切换和锁竞争的消耗
IO多路复⽤,基于Linux的select/epoll机制,提高大量连接时的并发度
高效的数据结构内单复数
允许单个线程或进程同时监控多个I/O流(如文件或网络连接),并在发生I/O事件时(可读可写、连接就绪)处理,提高系统并发度
select:每次都要遍历所有文件描述符的状态,最多监控1024个文件描述符
poll:使用链表存储文件描述符状态,没有文件描述符数量的限制,但仍需要遍历
epoll:事件驱动机制,只处理发生事件的文件描述符,避免遍历。适用监控大量文件描述符的场景
主线程负责监听I/O事件(连接、可读事件)、解析和执行客户端命令、将响应数据放入缓冲区。辅助线程负责:读取客户端请求数据、将主线程生成的响应数据发送回客户端。持久化、集群同步。因为Redis性能瓶颈在⽹络IO,使⽤多线程能提升IO读写效率
.2. 数据类型?场景?指令?底层数据结构?从大量key中查找前缀key?
s排过期缓锁消(校)友订
String:存储字符串,最大512MB。缓存JSON、token、session、二进制图片、音视频;计数(点赞、访问)/限速器、分布式锁
## 设置value并覆盖
set key value
get key
## 将value原子性的增/减 1/crement
incr/decr key
incrby/decrby key increment/decrement
底层实现:动态字符串simple dynamic String SDS
embstr编码:长度<=39字(因为只分配1块连续内存,读取快,只用释放1块内存;raw分配2块不~,~慢,~2~)
raw编码:append修改embstr字符串会转换为raw
int
不用C的字符串原因
支持保存文本和二进制数据 C不能存\0
保存字符串⻓度信息将获取长度时间复杂度降低到O(1)
拼接字符串不会造成缓冲区溢出
len
alloc,分配给字符数组的空间长度。通过alloc - len计算剩余的空间大小,
flags,用来表示不同类型的 SDS。sdshdr5、8、16、32、64,它们的len 和 alloc 成员变量的数据类型不同,保证8字节对齐,节省内存
buf[],小于1MB翻倍扩容,超过 1 MB,每次+1MB。减少内存分配次数
list:字符串有序集合,可重复。(消息)队列(到货通知、邮件发送),堆,栈,关注、粉丝列表
## 头/尾部添加多个value,返回个数,为0则键删除
lpush/rpush key value1 value2..
## 返回从start到end的元素的值 0 -1查全部
lrange key start end
## 返回并删除链表中的头/尾部value
lpop/rpop key
## 返回value数量
llen key
底层实现:
元素个数小于512(list-max-ziplist-entries),大小小于64字节(list-max-ziplist-value)使用压缩列表否则双向链表linkedlist
Redis3.2+ 只用quicklist
由多个压缩列表组成的双向链表,避免大量链表指针带来的内存消耗和ziplist更新导致的大量性能损耗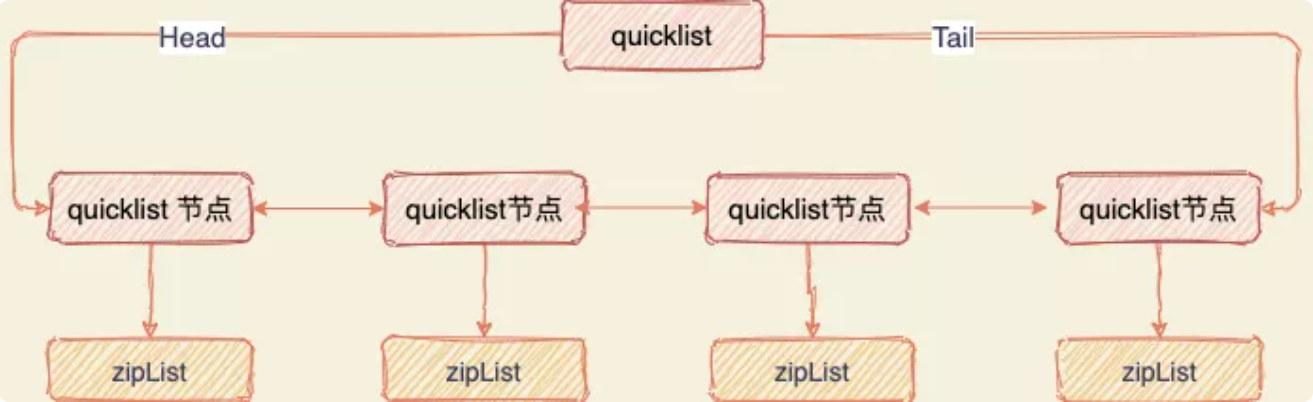
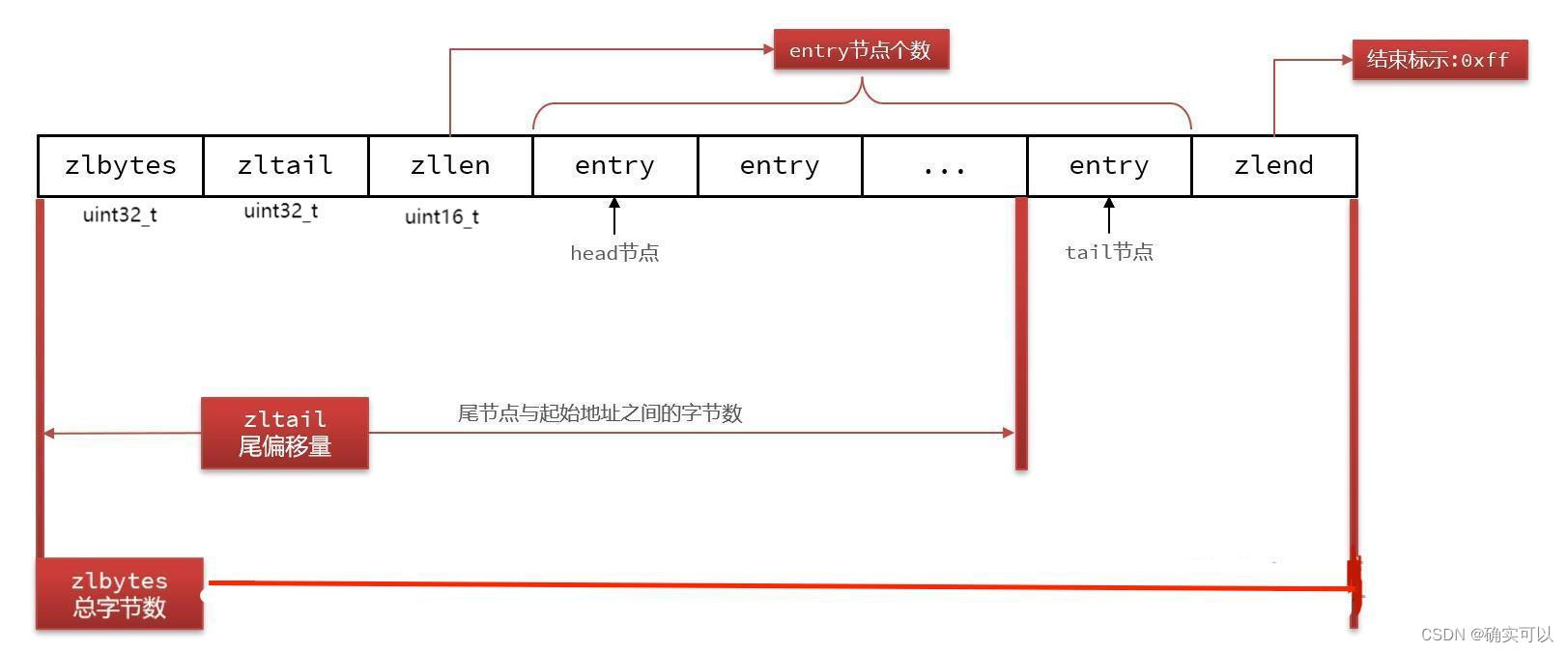
压缩列表ziplist 有序,节约内存。内存连续,大小有限,增删时连锁更新导致的大量性能损耗。组成如下
zlbytes:总字节数,4字节,最多有2^32-1个字节
zltail:头部到末尾元素的长度。4字节
zllen:元素个数,2字节。最多2^16-1个
entry:存储的元素
zlend:结尾,1字节,0xFF
typedef struct entry{// 10字节
previous_entry_length 前⼀个entrylen,常为1字节
encoding:编码格式,常为1字节 字符串和整数
content:保存实际数据
}
set:字符串无序集合、不重复,点赞;共同关注、标签、好友关系(交集、并集和差集)
## 添加/删除,点赞/收藏,取消点赞/收藏
sadd/srem key value1、value2…
## 返回所有的成员 所有点赞/收藏用户
smembers key
## 返回成员的数量 点赞数
scard key
## 判断指定的成员是否存在,1存在,0不在或者key不存在 是否点赞/收藏
sismember key member
## 随机返回一个成员
srandmember key
## 与key顺序有关。返回差集、交集、并集
sdiff/sinter/sunion key1 key2
## 求key1、key2差集、交集、并集存储在destination上
sdiffstore/sinterstore/sunionstore destination key1 key2
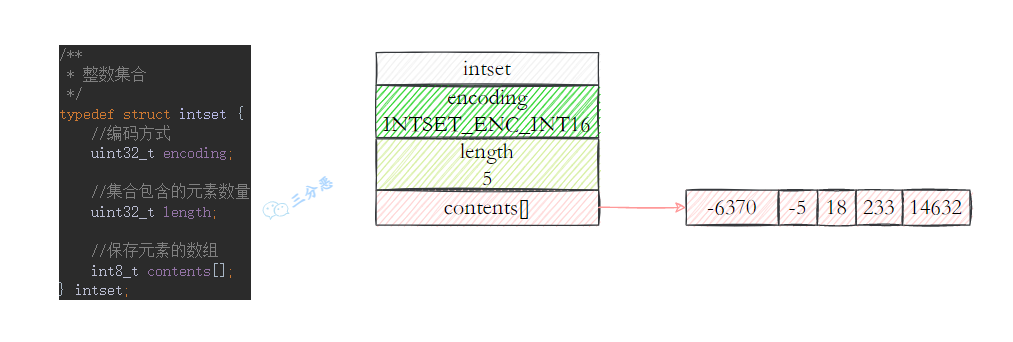
底层实现:整数元素个数小于512(set-maxintset-entries)用整数集合。数组实现。否则哈希表
sorted set:有序集合。不重复,按分数升序。添加、删除或更新的时间复杂度O(log n)。排名/排行榜订单30分钟自动取消
# 添加元素
zadd key score member score2 member2 …
## 删除元素返回数量
zrem key member[member…]
## 指定成员分数增加increment。并返回新分数
zincrby key increment member
## 获取成员数量
zcard key
## 获取分数在[min,max]之间的成员数量
zcount key min max
## 返回start-end的成员及分数/倒序 【0-1】返回所有
zrange/zrerange key start end [withscores]
## 返回分数为min max的成员及分数升序
zrangebyscore key min max [withscores] [limit offset count]
## 返回成员的排名,从小到大/从大到小
zrank/zrevrank key member
## 返回成员的分数
zscore key member
底层实现:
元素个数小于128(zset-max-ziplist-entries),大小小于64字节(zset-max-ziplist-value)用压缩列表否则用跳表+hash表
7.0+ listpack代替ziplist,其他不变
listpack,比ziplist更节省内存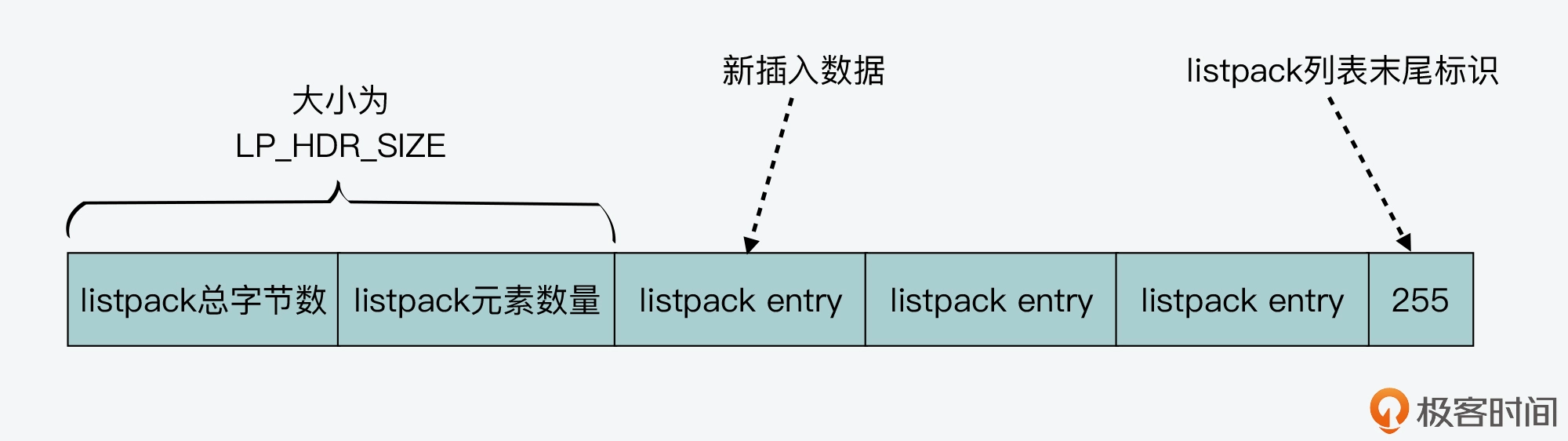
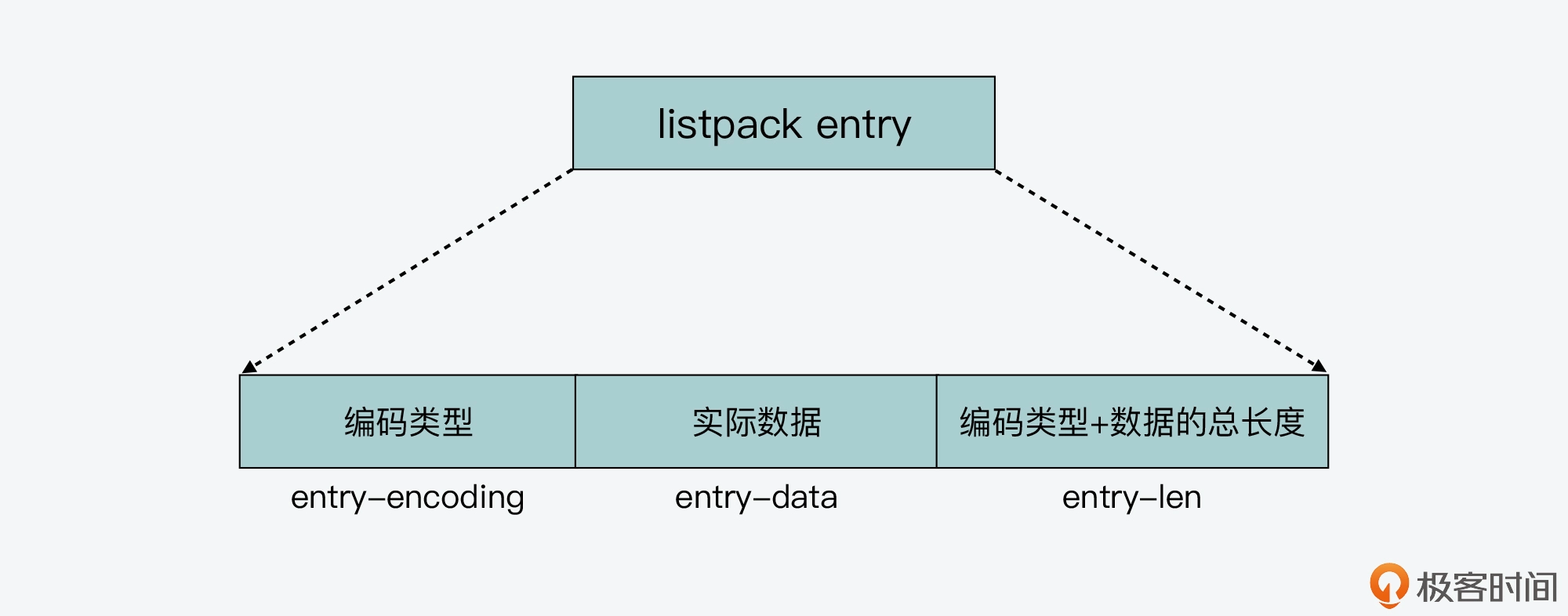
解决ziplist的连锁更新问题,listpack元素保存当前元素的编码类型、数据,编码类型和数据的长度。优化元素内字段的顺序,来保证既可以从前也可以向后遍历。
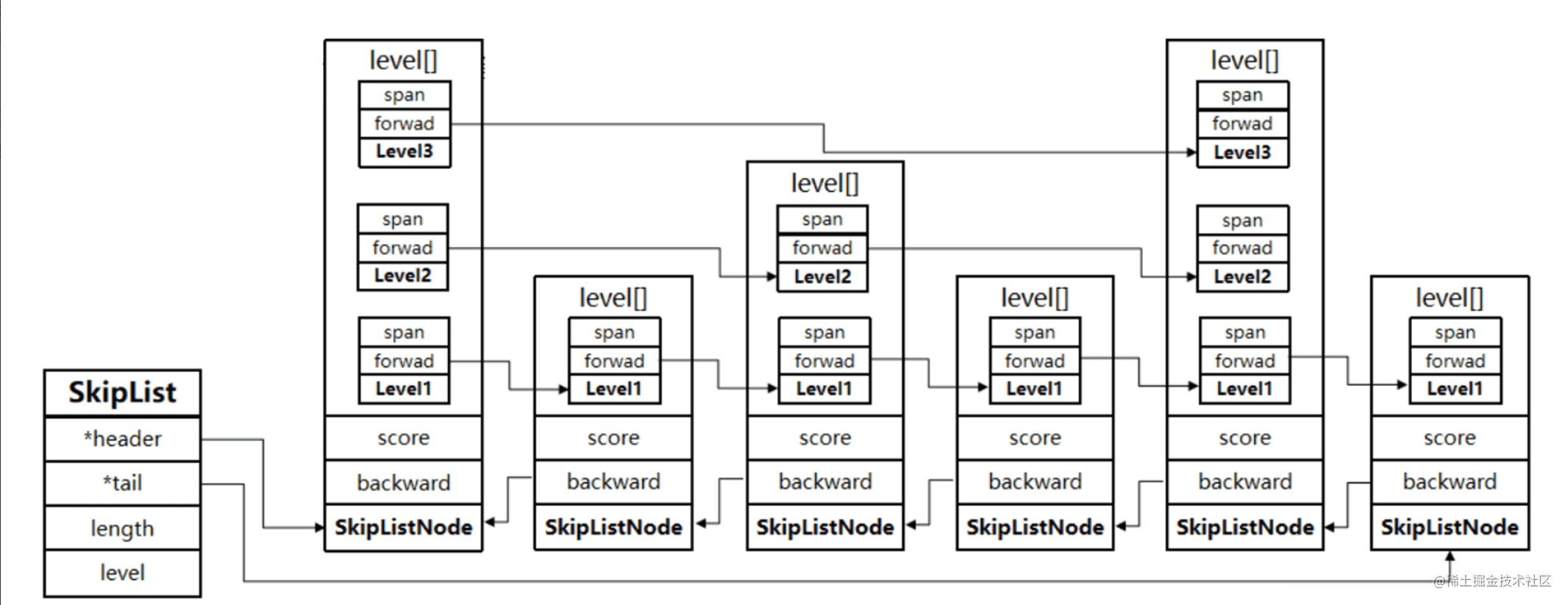
跳表skiplist:有序多层链表,在每个节点中维持多个指向其它节点的指针,能快速访问节点。平均O(logN),最坏O(N)复杂度
zskiplist保存表头、表尾、⻓度、层高等
zskiplistNode表示跳表节点,层⾼不固定,保存了当前节点的分值和成员对象的指针
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;//层高
} zskiplist;
typedef struct zskiplistNode {
robj *obj;//value
double score;//分值
struct zskiplistNode *backward;// 后退指针
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;// 跨度,记录两个节点之间的距离,用来计算排位rank,查找时记录累计值
} level[];//每一层指向的节点level[0]就是第0层,每次插入时随机生成层数表示高度
} zskiplistNode;
//插入操作:使用一个数组通过比较大小记录新数据在每层插入的位置,
//根据随机生成层数,从底层开始往上层插入该数据
//查找操作:从最高层往下通过比较大小搜索链表,辅助节点的下个节点决定值是否存在
//删除操作:使用一个数组通过比较大小记录新数据在每层删除的位置,
//辅助节点的下个节点决定值是否存在,如果存在,则根据数组从底层开始往上层删除该节点
//排名操作:使用辅助节点从顶层向下遍历并从0递增排名
//范围排名:使用辅助节点从头节点遍历第一层链表即可

hash:键值对集合,保存对象(用户信息)、分组,购物车对象
hset key field value
hget key field
# 获取所有filed-vaule
hgetall key
HDEL key field
## 判断filed是否存在
hexists key field value
## 获取field的数量
hlen key
hincrby key field increment
底层实现:
元素的长度都小于64字节(hash-max-ziplist-value)且数量小于512个( hash-max-ziplist-entries)用压缩列表ziplist,否则用哈希表/字典dict
7.0+ listpack代替ziplist
字典dict:⽤于保存键值对,使⽤hash表实现
多一个hash表用于rehash,在扩缩容时,为了高可用,rehash的过程是渐进式的
哈希表的负载因子(动态) = 哈希表已保存的节点/哈希表大小。判断是否需要对哈希表进行扩容或者收缩,通过rehash实现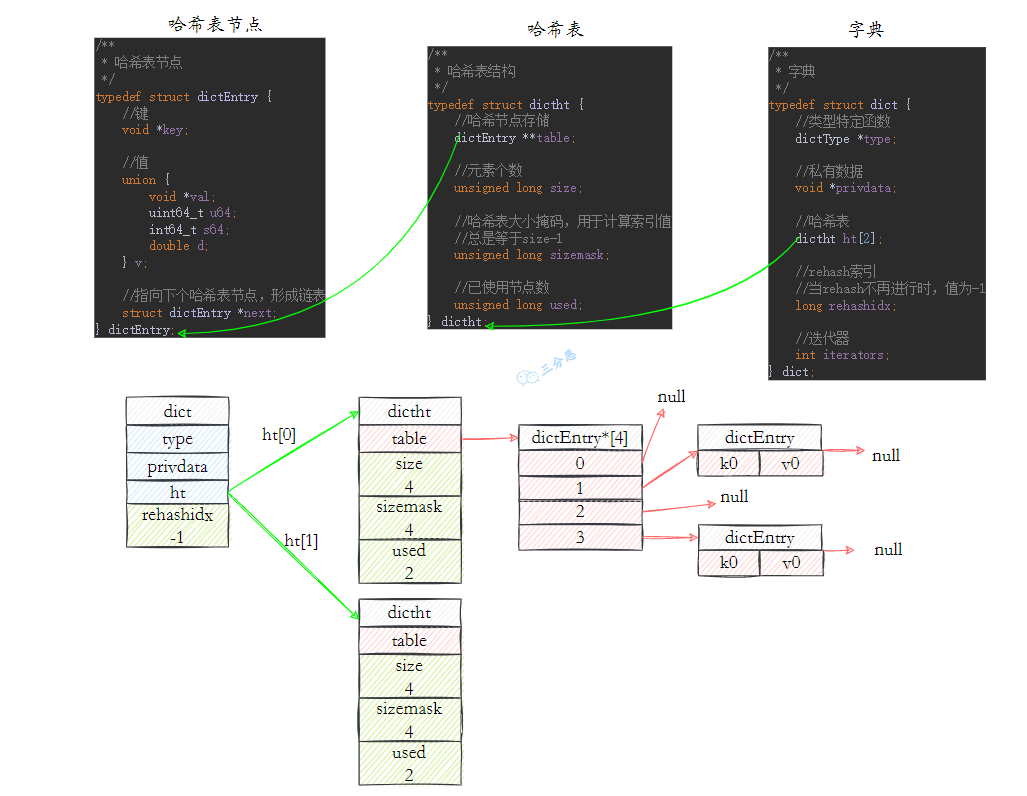
扩容时机
没有执行BGSAVE或BGREWRITEAOF命令,且哈希表负载因子大于等于1
执行BGSAVE或BGREWRITEAOF命令,且哈希表负载因子大于等于5
收缩时机:哈希表负载因子小于0.1时
Bitmap:bit数组,节省空间。判断用户是否在线,用户每个月签到情况,连续签到用户总数
设置用户是否已登陆,用户ID offset,1在线,0下线 获取用户是否在线
SETBIT key offset value
GETBIT key offset
统计用户每个月签到情况
key = uid:sign:{userId}:{yyyyMM},offset = 日期-1(offset从0开始)
记录、是否打卡、打卡次数、key月首次打卡日期
SETBIT、GETBIT、BITCOUNT、BITPOS key 1(查找第一个设置为指定值1的位位置offset)
统计连续签到7天用户总数
一亿个位的Bitmap约占12MB(10^8/8/1024/1024),7天的Bitmap占用84MB。
同时给Bitmap设置过期时间,节省内存
SETBIT 20210500 userId 1 //记录用户在2021年5月1日打卡
记录用户在2021年5月1-7日连续打卡的userId和状态到destinationmap
BITOP AND、OR、NOT、XOR destinationmap 20210500 20210501...
BITCOUNT destinationmap //查询destinationmap连续打卡总人数
BloomFilter、RedisSearch、Redis-ML、JSON
底层数据结构
使用SDS,把每个字节数组的8个bit位利用起来,每个bit位表示0或1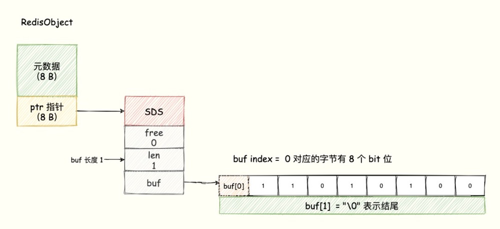
HyperLogLog 2.8+:海量数据基数统计的场景,比如百万级网页 UV 计数等;
GEO 3.2+:存储地理位置信息的场景,比如滴滴叫车;
Stream 5.0+:消息队列,自动生成全局唯一消息ID,能以消费组形式消费数据
其他命令
# 获取所有与pattern匹配的,* 多个字符,?任意一个字符
key keys pattern
del key1 key2
## 判断key是否存在,1在,0不在
exists key
## 设置过期时间
expire key second
## 获取剩余超时时间,没超时则-1
ttl key
## 返回类型,不存在返回none
type key
## 清除过期时间。Key持久化。-1 永久保存
persist key
键值对中的key是字符串对象,而value可以是字符串、集合数据类型的对象,比如List 对象、Hash 对象
Redis使用哈希表保存所有键值对,查找键值对时间复杂度O(1)。哈希表是一个数组,数组中的元素叫做哈希桶。哈希桶保存指向键值对数据的指针(dictEntry*),包括void * key 和 void * value 指针,分别指向了实际的键对象和值对象,通过指针能找到键值对数据,void * key 和 void * value 指针指向的是 Redis 对象 用redisObject表示,包括以下字段
type:查看对象数据类型type {key}
encoding:编码方式。与内存占用有关 object encoding key查看
lru:对象最后一次被访问的时间,用于LRU算法。
refcount:object refcount {key}获取当前对象引用的次数。为0时被回收。
*ptr:存储整数和指向数据的指针
keys指令阻塞地扫出指定模式的key列表(keys xxx*),直到指令执行完毕
scan指令非阻塞~,但要去重,但花费时间会长。(scan 0 match "api_"...->scan 100 match "api_")直到返回的下一次调用的cursor为0
.3. 持久化方式?触发条件?区别?优缺点?混合持久化?√选择?数据恢复?
Rdb持久化默认:通过定期或手动创建快照,将内存中的数据保存到磁盘文件dump.rdb
SAVE命令同步执行RDB持久化。会阻塞客户端请求
BGSAVE命令fork出一个子进程执行RDB持久化并立即返回,不~。推荐使用
SHUTDOWN命令
主从复制时主服务器没有RDB文件时
redis.conf中save <seconds> <changes>指令配置
save 900 1
save 300 10 在300s内至少有10次数据修改时RDB执行持久化
save 60 10000
AOF持久化:记录每个写操作命令并追加到AOF文件中,工作流程
命令写入append:将写命令追加到AOF缓冲区buffer的末尾
文件同步sync:将缓冲区中的命令持久化到磁盘中的AOF文件,同步策略包括:
always:每次写命令都同步到AOF文件,安全性高,但性能受磁盘I/O的延迟影响
everysec默认:每秒同步,性能和数据安全性好。宕机时可能丢失最后一秒的数据
no:由AOF关闭、Redis关闭或操作系统内核的缓存冲洗策略触发。宕机时丢失的数据量可能更多
文件重写rewrite:AOF文件会随着操作增多不断增长,重写AOF文件能减小AOF文件大小
由BGREWRITEAOF命令创建子进程执行重写操作,将内存中的状态转换为写命令并保存到新AOF文件,避免阻塞主进程。重写过程中,新的写命令会继续追加到旧文件和缓冲区中。重写完成后,缓冲区中的命令追加到新AOF文件,确保数据的完整性
重启加载load:Redis启动时读取AOF文件中的命令恢复数据库的状态
appendonly on #默认no
appendfilename "appendonly.aof"
appendfsync always
auto-aof-rewrite-percentage 100 #增长到原大小的100%时触发重写
auto-aof-rewrite-min-size 64mb #AOF文件达到64MB才重写
保存AOF文件时将RDB的快照作为文件开头,后续写操作追加到这个文件中。重启时利用RDB的快照部分快速恢复大量数据和AOF日志确保恢复过程中数据的一致性
RDB文件相对小,恢复速度快,适合全量备份。但数据容易丢失
AOF数据不易丢失,适合增量备份。但文件相对大,恢复速度慢
AOF增量持久化,保证数据不丢失; RDB全量持久化,保证数据快速恢复;同时启用保证性能和数据完整性
AOF开启且AOF文件存在时加载AOF文件,AOF关闭或者AOF文件不存在时加载RDB文件
.4. 如何实现高可用?主从复制?作用?拓扑结构?工作流程?数据同步的方式?存在哪些问题呢/不推荐Redis读写分离?Redis Sentinel?原理?领导哨兵、新主节点选举流程?最少哨兵节点个数?Redis集群?原理?集群中数据如何分区、伸缩?最小物理节点、实例数?
Master-Slave Replication将Redis服务器(主节点master)的数据,复制到其他Redis服务器(从节点slave)
数据热备份
故障恢复:主节点宕机时由从节点提供服务
负载均衡:主节点提供写服务,从节点提供读服务。在写少读多场景下多个从节点分担读负载,提高并发量
按拓扑复杂性分
一主一从结构:主节点宕机时从节点提供故障转移支持
一主多从(星形拓扑)结构:*,每个中心是主服务器,角是从服务器
树状主从(树状拓扑)结构:引入复制中间层降低主节点负载和需要传送给从节点的数据量,多叉树
slaveof 127.0.0.1 6380
保存主节点master信息:ip和port
主从建立连接
从节点发送ping命令检测主从之间网络套接字是否可用、主节点当前是否可接受处理命令
权限验证:如果主节点要求密码验证,从节点必须正确的密码才能通过验证。
同步数据集:主节点把数据发送给从节点
命令持续复制:主节点持续把写命令发送给从节点,保证主从数据一致性保连发权同复
Redis2.8+使用psync{runId}{offset}命令完成主从数据同步,同步过程分为
全量复制:用于初次复制,把全部数据一次性发送给从节点,数据量大时影响性能
1.从服务器执行replicaof命令并发送psync ? -1(第一次复制从节点没有复制偏移量和主节点的运行ID)
2.主节点解析为全量复制回复+FULLRESYNC响应
3.从节点接收主节点的响应数据保存运行ID和偏移量offset
4.主节点执行bgsave保存RDB文件
5,主节点给从节点发送RDB文件,从节点把接收的RDB文件保存在本地
6.从节点接收RDB快照到接收完成期间,主节点会把写命令数据保存在复制客户端缓冲区内,当从节点加载完RDB文件后,主节点再把缓冲区内的数据发送给从节点,保证主从数据一致性
7.从节点接收完主节点传送来的全部数据后会清空自身旧数据并加载RDB文件
8.从节点加载完RDB后,如果节点开启了AOF则做bgrewriteaof操作,保证AOF持久化文件可用
部分复制:当出现网络闪断或者命令丢失等异常情况时,主节点会将复制积压缓冲区内存在的数据发送给从节点,保持主从数据一致性
1.当主从节点网络出现中断时并超过repl-timeout时间,主节点会认为从节点故障并中断复制连接
2.主节点用环形复制积压缓冲区repl_backlog_buffer(默认1MB,缓冲区写满后会覆盖之前的数据)保存写命令数据。master_repl_offset记录主服务器写到的位置,slave_repl_offset记录从服务器读到的位置
3.当主从节点网络恢复后,从节点会再次连上主节点
4.从节点发送 psync {slave_repl_offset} {主节点的运行ID}命令给主节点
5.主节点核对参数runId并根据参数slave_repl_offset和master_repl_offset在复制积压缓冲区查找,如果master_repl_offset-slave_repl_offset小于repl_backlog_buffer大小,则发送+CONTINUE响应进行部分复制。否则全量复制
6.主节点根据偏移量把复制积压缓冲区里的数据发送给从节点
根据second(主从重连的平均时间(秒))* write_size_per_second(主服务器平均每秒产生的写命令数据量大小)修改redis.conf的repl-backlog-size 1m增大repl_backlog_buffer缓冲区,减少覆盖概率
无法自动故障转移:主节点故障时需要手动将从节点改为主节点,同时修改应用的主节点地址、命令其他从节点去复制新的主节点(高可用)
主节点的写和存储能力受到单机的限制(分布式)
用于监控主从复制状态、自动故障转移和系统消息通知。由哨兵节点(不存储数据,监控数据节点。)和数据节点(主、从节点)组成。初始化sentinel monitor <master-name> <ip> <redis-port> <quorum>
哨兵功能通检自配
通知:向管理员或应用程序发送状态变化通知
监控:检查主、从节点是否运作正常
自动故障转移:当主节点异常时,将其中一个从节点晋升为主节点,命令从节点复制新主节点
配置提供者: 客户端初始化时通过哨兵获得主节点地址
哨兵模式通过哨兵节点完成对数据节点的、领导者sentinel选举、故障转移。定下领骨
定时监控10\2\1
每10秒向数据节点发送info命令获取最新的拓扑结构
每2秒向数据节点的sentinel:hello频道上发送对于主节点的判断以及Sentinel节点信息
每秒向其他节点(主、从、其余Sentinel节点)发送ping命令做心跳检测确认是否可达
主客观下线
~,当节点超过down-after-milliseconds没有回复,将该节点标记为主观下线
当Sentinel标记主节点主观下线时,向其他 Sentinel 节点发送 is-master-down-by-addr 命令询问对主节点的判断,当超过 <quorum>(哨兵个数的二分之一加1)个Sentinel节点认为主节点主观下线,该Sentinel节点会标记主节点客观下线
领导者哨兵选举
领导者Sentinel节点负责故障转移:
选出主节点:在从节点列表中选出一个节点作为新的主节点
设置主节点:领对从节点执行slaveof no one 命令让其成为主节点
从节点同步:向剩余的从节点发送SLAVEOF ip port命令它们复制新主节点
通知客户端:向+switch-master频道将新主节点的IP等信息通过发布订阅机制通知给客户端
原节点转从:发现原主节点恢复后发送SLAVEOF IP port命令它复制新主节点
过滤:主观下线、5秒内没有响应ping、与主节点失联超过down-after-milliseconds*10秒
选择slave-priority优先级高的、复制偏移量最大、节点runid最小的从节点
使用Raft算法实现
哨兵节点标记主节点主观下线时会向其他哨兵节点发送is-master-down-by-addr命令请求将自己设置为领导者
收到命令的哨兵节点,如果没有同意过其他Sentinel节点的请求,将同意该请求,否则拒绝
如果Sentinel节点发现票数已经大于等于max(quorum, num/2+1),那么它将成为领导者
如果没有选举出领导者,将进入下次选举
3个。一个哨兵要成为领导者必须获得2票。如果有哨兵宕机就没法达到2票。3个哨兵节点挂了2个?人工或者增加哨兵节点
主从复制存在高可用和分布式的问题,哨兵解决了高可用的问题
通过数据分区来实现数据的分布式存储、自动故障转移实现高可用的分布式部署方案
数据分区:通过分片的方式将数据存储到多个节点,每个主节点都可以处理读写请求,提高存储容量和响应能力
高可用:集群支持主从复制和自动故障转移,节点故障时不影响服务
数据分区规则余一虚
节点取余分区:键的哈希值对节点数量取余,然后将数据项放到对应节点上扩缩容时需大量数据迁移,因为节点总数改变影响取余结果
一致性哈希分区:将哈希值空间组织成环,节点映射到环上。数据项映射到顺时针的第一个节点上。扩缩容只影响哈希环中相邻节点,减少数据迁移。但节点分布不均匀和节点故障数据迁移导致负载不均匀
虚拟槽(哈希槽)分区,将键通过CRC16算法映射到固定的16384个槽,每个集群节点管理一定范围内的槽。槽可以灵活迁移,扩缩容平滑;数据分布均匀,Redis集群分区原理
假设系有4个节点分配16个槽(0-15);槽0-3、4-7、8-11、12-15位于节点node1、2、3、4
删除node2时将槽4-7重新分配即可,将槽4-5分配给node1,6分配给node3,7分配给node4,数据在节点上的分布仍然均匀。
增加node5时将槽分配给node5即可,将槽3、7、11、15分配给node5
取决于CRC16(key)%槽的个数结果。因为集群中槽数是2的14次方,保证扩容后大部分数据位置不变,只有少部分数据需要迁移到新槽
集群创建:完成数据分区
设置节点:每个节点配置cluster-enabled yes运行在集群模式下
节点握手:节点通过Gossip协议互相通信。客户端发起命令cluster meet{ip}{port}。完成节点握手后组成集群
分配槽slot:把所有数据映射到16384个槽。每个节点对应若干个槽,cluster add slots分配槽
故障转移:参考哨兵,集群中所有节点都要维护状态
故障发现:集群中节点每秒向其他节点发送ping消息,如果超过cluster-node-timeout没有收到其他节点回应pong消息,则改节点被标记为主观下线。 此节点状态会通过Gossip消息传播,当半数以上主节点都标记某个节点是主观下线时。该节点被标记为客观下线
故障恢复:如果下线节点是持有槽的主节点则需要在从节点中选出新主节点
资格检查:每个从节点检查与主节点断线时间,判断是否有资格替换故障的主节点。
准备选举时间:当从节点符合故障转移资格后,更新触发故障选举的时间,只有到达该时间后才能执行后续流程
发起选举:当从节点定时任务检测到达故障选举时间failover_auth_time到达后,发起选举流程
选举投票:持有槽的主节点处理故障选举消息。如集群内有N个持有槽的主节点代表有N张选票。由于每个主节点只能投票给一个从节点,因此只能有一个从节点获得N/2+1的选票
当从节点收集到足够的选票之后替换主节点
6个节点3主3从,3台物理机部署主节点,有2个主节点在一台机器上宕机时,从节点无法收集到3/2+1 个主节点选票将导致故障转移失败
.5. 缓存穿透,击穿,雪崩及解决√布隆过滤器?/大量key同一时间过期?/热key重建及问题?如何保证本地缓存和分布式缓存、缓存和数据库数据一致性?√过期键的删除策略?内存淘汰策略?内存优化?/内存不足处理?/如何保证数据都是热点数据?/如何提高Redis命中率?预热?方案?无底洞问题?解决?大key和热key?判断?问题?原因?处理?
缓存穿透:高频查询不存在的数据,请求每次都会穿过缓存去查询数据库。导致数据库压力大
- 缓存空对象:用于数据命中率低,实时性高,内存占用大,快速过期或者利用消息队列清理空对象节省内存;缓存和数据库短时间内数据不一致
- 布隆过滤器拦截:查询前先用布隆过滤器验证是key否存在,存在则查询缓存和数据库。用于数据命中率低、实时性低,内存占用少
缓存击穿:高频查询缓存中过期的数据,大量请求查询数据库,导致数据库压力大
- 加锁更新,当缓存没有数据时对key加锁,查询数据库后更新缓存并返回数据,后续请求从缓存中读取。降低数据库压力,数据一致性好,高并发情况下可能因为查询数据库或者大量计算重建缓存太慢导致死锁或者阻塞
- 异步刷新:将过期时间写入value,通过异步⽅式刷新过期时间,不阻塞。保证可用性,牺牲时效性。
缓存雪崩:大量的缓存同时过期或缓存服务器宕机,导致请求都到数据库上,导致数据库压力大
- 集群部署:避免单点故障,某节点故障时其他节点仍能服务。
- 多级缓存,本地进程一级缓存,redis二级缓存,不同级别的缓存设置的超时时间不同
- 随机过期时间,缓存过期时间加上随机值,避免同时过期
- 限流和降级:通过限流策略控制流量,在缓存失效时关闭非核心服务,保障核心服务
由位数组和k个哈希函数组成。添加元素时由k个哈希函数生成k个位置,并将这些位置设置为1。查询元素时如果k个哈希函数计算位置对应值中有0,则该元素不存在;如果所有位置的值都为1,则该元素可能存在。
内存占用小,查询效率高。哈希算法存在哈希碰撞。存在误判。不支持删除元素
本地缓存Guava、Redis分布式缓存
引入消息队列RocketMQ、RabbitMQ
设置本地缓存的过期时间,过期时从Redis同步
使用Pub/Sub机制,本地缓存订阅Redis缓存发生变化的消息,删除本地缓存消过订
产生原因:并发场景下旧数据更新到缓存中;缓存和DB的操作不在一个事务中导致数据不一致
删除缓存原因:删除缓存快,更新缓存时代价大(计算复杂\多表关联)
先删除缓存,后更新数据库
请求A删除缓存1,请求B读不到缓存读数据库1并写缓存1,请求A写数据库2,数据不一致
方案:串行写。写前淘汰缓存需要先获取该分布式锁。读请求时,发现缓存不存在需要先获取分布式锁
先更新数据库,后删除缓存
请求A读不到缓存读数据库1;请求B写数据库2并删除缓存,请求A写缓存1,数据不一致
缓存删除失败,并发导致写入了脏数据
问题1:概率低,缓存刚好失效、读写并发、B更新DB+删缓存时间小于A读DB+写缓存时间(因为写数DB加锁,通常比读DB时间长)
问题2:
消息队列保证缓存被删除。当数据库更新完成后发送更新事件到消息队列。有服务监听事件并负责删除缓存。缺点是业务耦合性强
数据库订阅+~。使用Canal监听MySQL的binlog,获取需要操作的数据。然后用公共服务获取订阅程序传来的信息删除缓存。降低了业务耦合性,但增加系统复杂度
延时双删防止脏数据。在第一次删除缓存后,过段时间再次删除。针对缓存不存在,但写入了脏数据的情况。在先删缓存,再更新数据库中出现多。时机要考量
设置缓存过期时间:降低数据不一致时间,缓存过期后达到一致双消过b
惰性删除:当访问key发现过期时才清除。节省CPU资源,内存占用大
定期删除:定期扫描一定数量的有过期时间的key并清除其中已过期的key。通过调整定时扫描的时间间隔和每次扫描的限定耗时,使得CPU和内存资源达到平衡。(expires字典保存key的过期时间数据,key是指向键空间中的某个键的指针,value是UNIX时间戳的过期时间) config get hz每秒执行其内部定时任务(如过期键的清理)的频次。通过CONFIG SET hz 20或者配置文件hz修改
Eviction Policies,Redis内存不足时的处理方式如下leftr
noeviction(默认):不淘汰数据,直接返回错误
volatile/allkeys-lru:从有过期时间的键/所有键中根据最近的使用时间淘汰最近最少使用的键
volatile/allkeys-lfu:从有过期时间的键/所有键中根据访问次数淘汰访问的次数最少的键
volatile/allkeys-random:从有过期时间的键/所有键中随机淘汰键
volatile-ttl:从有过期时间的键中淘汰即将过期(Time To Live存活时间)的键
获取/修改策略:config get maxmemory-policy、config set maxmemory-policy allkeys-lru、redis.conf:maxmemory-policy allkeys-lru
为了节省内存,Redis使用近似的LRU算法,通过随机采样maxmenory-samples(默认5个key)淘汰最近最少使用的key。maxmenory-samples越大,结果越接近于严格的LRU算法
文内策群
修改内存上限:redis.conf->maxmemory 100mb/config set maxmemory
修改内存淘汰策略
使用Redis集群模式横向扩容
内存优化
设置合理内存淘汰策略:使用allkeys-lru/lfu策略,基于数据使用频率和最近使用时间判断热点数据
设置合理过期时间:短生命周期数据设置较短TTL:如会话信息、临时状态,。长~:如热点配置、字典等
选择合适的数据结构:
多个字段存储在一个哈希中而不是多个键
当对象为整数且范围在[0-9999]时能用共享整数对象池节省内存
编码优化:字符串长度推荐小于39字节此时编码为embstr类型,只要分配一次内存。提高性能。
缩减键值对象:使用压缩算法压缩json,xml节省内存,如Snappy
控制key的数量
定期使用SCAN命令根据业务清理不需要或不常用的数据
缓存预热:Redis启动时或定期预加载业务中的热点数据到缓存中,以避免在系统运行初期由于缓存未命中导致的性能问题,减少首次访问时的延迟。数据量不大的时候,项目启动时初始化。数据量大的时候,定时任务刷新缓存起订
监控和分析热点数据
通过INFO命令或监控工具(RedisInsight、Prometheus等)实时监控热点数据。
命令统计:分析并优化被频繁访问的键。如果使用LFU内存淘汰策略,可根据访问频率来判断数据是否为热点数据
用scan [cursor] + object idletime {key} 命令批量查询长时间不访问的键进行清理降低内存占用
命中率越高则使用缓存的收益越高,性能越好(响应时间越短、吞吐量越高)
~、~、~
监控命中率和分析访问模式 使用INFO命令监控命中率指标keyspace_hits/(keyspace_hits+keyspace_misses),分析并优化的命中率低的key。通过访问日志和性能监控,分析常用的数据和访问模式,优化缓存策略
数据归档和清理 定期清理过期或不再使用的数据,对于不常用的数据,可以考虑将其转移到低成本的存储中,减少内存占用
为什么开启maxmemory和LRU淘汰策略后对象池无效?
LRU算法需要获取存储在redisObject对象的lru字段的对象最后被访问时间淘汰最长未访问数据,对象共享时多个引用共享同一个redisObject的lru字段,导致无法获取每个对象的最后访问时间
如果没有设置maxmemory则不会发生内存回收,所以共享对象池可以正常工作。
ziplist编码的值对象无法使用共享对象池,因为ziplist使用压缩且内存连续的结构,对象共享判断成本高
为什么只有整数对象池?复用率最大;整数比较时间复杂度为O(1),效率高,只保留一万个整数防止浪费内存。字符串比较时间复杂度为O(n)。hash,list比较则要O(n2)
集群随着redis节点增多性能没有提升反而下降
原因:客户端批量操作会涉及多次网络操作,随着节点的增多增大耗时;网络连接数变多,影响节点性能命池次
优化操作命令
减少网络通信次数
降低接入成本,例如客户端使用长连/连接池、NIO等
占用大内存的key,key的大小和成员数量来判定
value的大小超过10KB。hash,set,zset,list中存储过元素过万
其实大Key本身所带来的影响并不大,用户每秒钟请求它一两次的不会产生任何问题,最怕的就是大Key + 热Key双鬼拍门。常见的千兆网卡来计算,其最大传输速度为每秒钟128MB,那就意味着如果Redis的大Key为1MB、每秒钟有100多个请求打到该台服务器上,就能将这台Redis服务器的网卡打满,从而影响系统可用性。
客户端超时;读写操作严重占用带宽和CPU;Redis集群中数据倾斜;主动删除、被动删造成阻塞
String存储二进制文件,成员没有拆分,没有定期清除无用数据
redis-cli --bigkeys -a pwd统计每个数据类型的大Key。redis-rdb-tools分析rdb快照文件
删除大key:Redis4.0+,用UNLINK命令异步删除。其他版本用SCAN命令扫描key,然后判断删除
压缩和拆分key
当vaule是string时,使用序列化、压缩算法减小value,牺牲性能。或者拆分为不同的部分,使用multi get等操作事务读取
当value是list/set等,根据大小分片,元素计算后分到不同的片
短时间内被频繁访问的key。Key被请求的频率来判定
QPS集中在特定Key:总QPS 1w,一个Key的QPS 8k
带宽使用率集中在特定Key:一个哈希key拥有上千成员且大小为1M,每秒发送大量的HGETALL请求
CPU使用率集中在特定Key:一个拥有数万个成员的ZSET Key,每秒发送大量的ZRANGE请求
预期外的访问量增加,如热点新闻
占用大量CPU资源;整体流量不均衡(网络带宽、CPU 和内存资源)个别节点OPS过大,极端情况下甚至超过Redis的OPS(每秒钟处理的命令数)
客户端设置全局字典(key 和调用次数)记录
代理端Twemproxy、Codis监控
Redis服务端:统计热点key命令:redis-cli monitor;分析热Key。redis-cli --hotkeys
加⼊⼆级缓存,把热Key加载到JVM中,后续请求从JVM中读取。比如Guava。需要防止本地缓存过大
分散到不同的服务器,降低压⼒
// N 为 Redis 实例个数,M 为 N 的 2倍
const M = N * 2
//生成随机数
random = GenRandom(0, M)
//构造备份新 Key
bakHotKey = hotKey + "_" + random
data = redis.GET(bakHotKey)
if data == NULL {
data = redis.GET(hotKey)
if data == NULL {
data = GetFromDB()
// 可以利用原子锁来写入数据保证数据一致性
redis.SET(hotKey, data, expireTime)
redis.SET(bakHotKey, data, expireTime + GenRandom(0, 5))
} else {
redis.SET(bakHotKey, data, expireTime + GenRandom(0, 5))
}
}
.6. 如何实现异步、延时队列?事务?如何实现CAS操作?注意事项?原因?Lua 脚本?Pipelining?分布式锁?
1对1消息队列:使用list,lpush生产消息,brpop阻塞消费消息,list为空时阻塞,直到list有值或者超时
1对N消息队列:使用发布/订阅将消息发布到指定的频道(channel),订阅频道的客户端都能收到消息。但不可靠,在消费者下线时消息会丢失
多播的可持久化的消息队列:Redis5.0+的Stream
延时队列:使用zset,不推荐
添加任务:score任务的执行时间戳,value任务的内容。ZADD delay_queue 1617024000 task1
定期获取score小于当前时间戳的任务执行。ZREMRANGEBYSCORE delay_queue -inf 1617024000
删除任务:ZREM delay_queue task1
事务将多个命令一次性按照顺序执行
multi:开启事务,后续命令加入到队列中并没有执行
exec:执行事务,MULTI队列中的命令被原子执行
discard:在EXEC之前取消事务,清空事务队列
watch:监视多个key,如果事务执行exec前key被修改,那么事务被取消并且返回一个错误
不支持回滚,调用EXEC命令后所有命令都会执行,即使有些命令执行失败
Redis设计重点是实现高性能基于内存的数据存储系统,事务回滚需要额外的资源和时间来管理和执行,违背设计目标
Lua脚本用于多条命令一次性原子执行
提供客户端多条命令打包发送给服务端执行的方式:Pipelining(管道) 、 Transactions(事务) 和 Lua Scripts(Lua 脚本) 。
节省了RTT:减少了服务端网络调用次数
减少了上下文切换:当客户端/服务端需要从网络中读写数据时都需要系统调用,从用户态切换到内核态,再从内核态切换回用户态。产生一次上下文切换
SET key value NX PX 30000加锁 del key释放锁
key锁名、NX键不存在时设置并返回true,否则不设置并返回false,PX表示过期时间,单位毫秒,防止死锁
缺点:只在单节点上加锁。可能因为主从复制延时导致锁丢失
对应Redisson的普通锁tryLockInnerAsync通过Lua脚本封装命令
使用Redission的Redlock,由RedissonMultiLock实现,解决分布式锁丢失的问题。
同时向多个redis节点使用唯一的key获取锁,并设置网络连接和响应超时时间,应该小于锁的失效时间。超时时间结束后向其他实例获取锁。
客户端用当前时间减去获取锁时间得到获取锁使用的时间。当从N/2+1的Redis节点获取到锁,并且使用的时间小于锁失效时间时,锁获取成功。
key的真正有效时间等于有效时间减去获取锁所使用的时间
如果获取锁失败(没有N/2+1个Redis实例取到锁或者取锁时间超过有效时间),客户端要给所有Redis节点解锁(防止某些节点获取到锁但是客户端没有得到响应而导致锁不能重新获取)
.7. Redis部署?常见性能问题和解决方案?阻塞产生原因?怎么解决?健康指标?
10台机器,5主5从,5个节点提供读写服务,每个节点的读写高峰qps可能达到每秒5万,5台机器最多是25万qps
32G内存+8核CPU+1T磁盘,分配10G内存给redis,生产环境Redis内存尽量不要超过10G,5台机器对外提供读写共有50G内存。
商品数据,每条数据是10kb。常驻内存的是 200 万条商品数据,占用内存是 20G ,仅仅不到总内存的50% 。目前高峰期3500左右qps
Master最好不要持久化,特别是RDB。因为save命令调度rdbSave函数阻塞主线程,当快照比较大时性能差,而AOF持久化,如果不重写AOF文件,AOF文件过大会影响重启的恢复速度
关键数据在Slave开启AOF备份数据,策略为每秒同步一次
Slave和Master最好在同一个局域网内保证主从复制的速度和连接的稳定性
避免在压力大的主库上增加从库。推荐从上挂载其它的从
Master调用BGREWRITEAOF重写AOF文件会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象
主从复制用单向链表结构是Master更稳定,方便解决单点故障问题,Master宕机时用Slave1做Master,其他不变
慢查询Slow Queries slowlog get{n}获取最近的n条慢查询命令,避免使用大数据量的操作,使用SCAN替代KEYS等。
阻塞型命令BLPOP ,wait等 限制阻塞时间或避免使用
内存不足,内存频繁回收 合理设置maxmemory,增加物理机内存,或分布式部署,使用LRU、LFU淘汰策略。减少内存压力
网络延迟 主从复制延迟导致主节点阻塞,优化网络配置,设置空闲连接超时
AOF重写和RDB持久化 调整持久化策略auto-aof-rewrite-percentage 和 auto-aof-rewrite-min-size 配置,异步执行重写和快照。
大数据量删除 使用UNLINK异步删除,避免阻塞
客户端缓冲区过载 限制缓冲区大小,使用分布式消息队列处理复杂的消息发布
存活情况:通过命令PING的响应是否是PONG来判断
连接数:通过命令info Clients查看,connected_clients建议不超过5000,rejected_connections如果大于0需要排查是连接池配置不合理还是连接服务过多等。blocked_clients,可能list数据类型的BLPOP或者BRPOP命令引起,最好为0
内存峰值:最大内存不超过20G,为了防止发生swap导致Redis性能骤降,甚至内存超标导致被系统kill,建议used_memory_peak的值与maxmemory的值有个安全区间,例如1G,那么used_memory_peak的值不能超过9663676416(9G)。监控maxmemory不能少于5G。
内存碎片率:mem_fragmentation_ratio=used_memory_rss/used_memory,如果是4.0-只能重启。而redis4.0+优化内存碎片率问题。在redis.conf中有ACTIVE DEFRAGMENTATION:碎片整理允许Redis压缩内存空间,从而回收内存。默认是关闭的,命令CONFIG SET activedefrag yes热启动。当这个值大于1时,表示分配的内存超过实际使用的内存,数值越大,碎片率越严重。当这个值小于1时表示发生了swap,即可用内存不够。建议used_memory至少1G以上才考虑对内存碎片率进行监控。
缓存命中率:建议0.9+
OPS instantaneous_ops_per_sec缓存的OPS,查看不同时间段不同业务波动是否合理
持久化:rdb_last_bgsave_status/aof_last_bgrewrite_status,最近一次RDB/AOF持久化都应该是"ok"。监控fork耗时latest_fork_usec太大可能超时
失效KEY:建议所有的key都设置expire属性,通过命令info Keyspace得到key的数量和设置了expire属性的key的属性,且expires需要等于keys:
慢日志