java问题解决
定位问题:
控制台查看错误日志
用可视化/命令行性能监控和故障处理工具
linux工具
查询端口连接数netstat -nat | grep 12200 –c
查看网络流量。cat /proc/net/dev
查看系统平均负载。cat /proc/loadavg
查看系统内存情况。cat /proc/meminfo
查看CPU的利用率。cat /proc/stat
top列出所有进程资源占用情况。找到CPU或内存高的进程,top -Hp PID列出具体进程线程占用资源情况
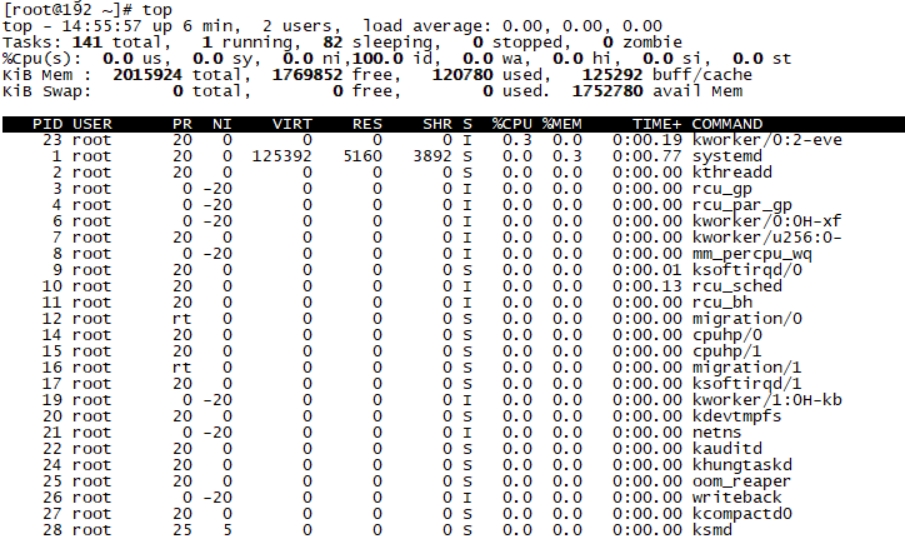
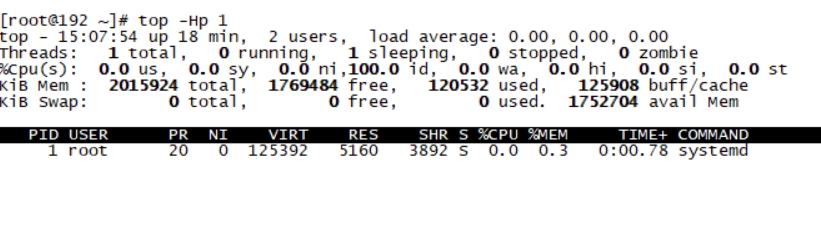
JDK性能监控工具
jps:虚拟机进程查看
jstat:虚拟机运行时信息查看
查看概况jstat -gcutil PID 1000 5监控gc,每秒输出一次,共5次
S0、S1、E、O、M:Survivor空间0和1、Eden区、老年代、Metaspace的使用率(百分比)。
CCS:压缩类空间的使用率。
YGC、FGC:Minor、Full GC次数。
YGCT、FGCT:Minor、Full GC耗时(秒)。
GCT:GC总耗时(秒)。

查询详细jstat -gc -h3 PID 250 10监控gc,每三行输出一次表头 ,每250ms 输出一次,一共 10 次。
S0C、S1C、S0U、S1U:Survivor空间0和1的容量(Capacity)和使用量(Usage)。
EC、EU/OC、OU/MC、MU:Eden区/老年代/Metaspace元数据区的容量和使用量KB。
CCSC、CCSU:压缩类空间的容量和使用量(如果存在)。
YGC、YGCT/FGC、FGCT:Minor/:Full GC(新生代GC)的次数和总耗时。
GCT:GC总耗时(Minor GC和Full GC的总和)。

jmap:内存映像(导出)
jmap -histo PID | head -20 查看堆内存占用空间最大的前20个对象类型 如果GC次数频繁,而且每次回收的内存空间正常,那是因为对象创建速度快导致内存一直占用很高 如果每次回收的内存非常少,那么可能因为内存泄露导致内存一直无法被回收 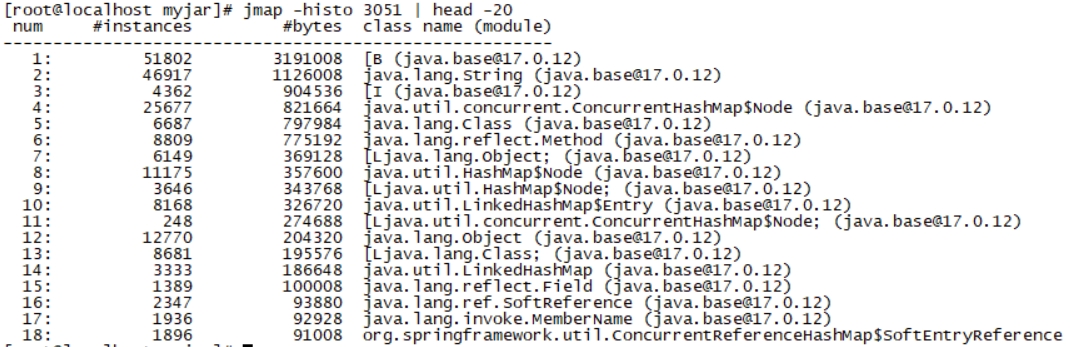导出堆内存多次
(推荐)jdk8-:jmap ‐dump:format=b,file=/tmp/dump.hprof pid
jdk9+:jhsdb jmap --binaryheap --dumpfile heap.hprof --pid pid
开启JVM参数会stw:‐XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./heapdump.hprof溢出时生成java_pidxxxx.hprof
jhat:堆转储快照分析
jhat工具:jhat ‐port 9999 /tmp/dump.dat ,访问http://ip:9999 通过OQL查询
jstack:Java 堆栈跟踪
打印堆栈信息jstack [pid] | grep -A 10 [nid = tid的十六进制 printf "%x\n" jstack中cpu最高的线程id]
定时多次导出该线程的堆栈信息jstack pid > log.txt
重点关注:WAITING/BLOCKED,根据锁的地址找到是哪个线程持有<xx>这把锁,里面有代码行数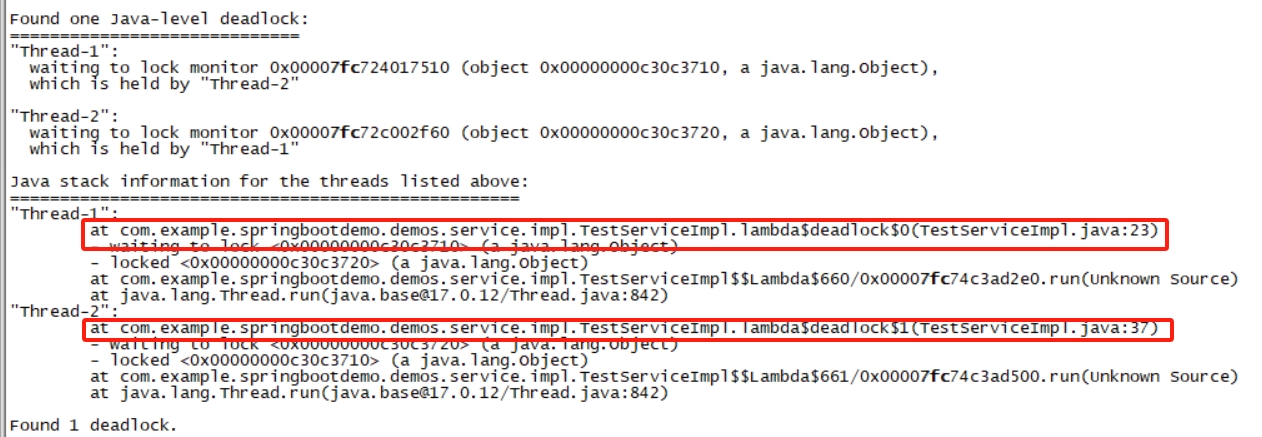
JConsole
VisualVM查看堆栈日志
(推荐)jdk11-内置jvisualvm,jdk11+下载visualvm工具,配置本地etc/visualvm_jdkhome:菜单 > 文件 > 装入dump.hprof文件,通过summary查询;或者远程连接别的jvm
Dcom.sun.management.jmxremote # 允许用JMX远程管理
Dcom.sun.management.jmxremote.port=9999 # 端口
Dcom.sun.management.jmxremote.authenticate=false # 不进行身份认证,任何用
Dcom.sun.management.jmxremote.ssl=false # 不用ssl
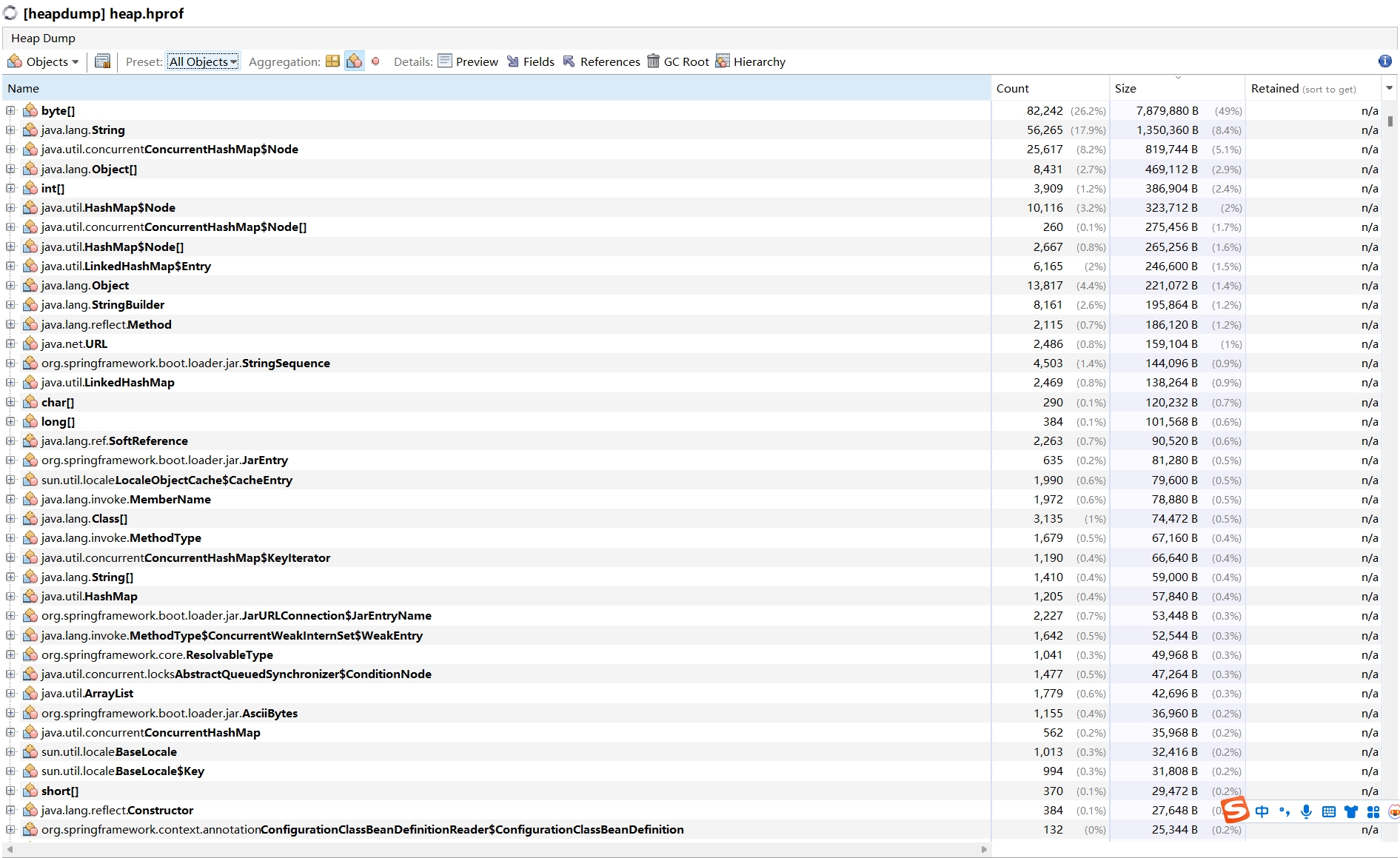
MAT Java 堆内存分析工具
Eclipse的MAT工具,免费,help>marketplace>MemoryMemory Analyzer安装,
菜单windows>Perspective>Open Perspective>MemoryMemory Analyzer
File>Open Heap Dump打开dump.hprof查看Leak Suspects
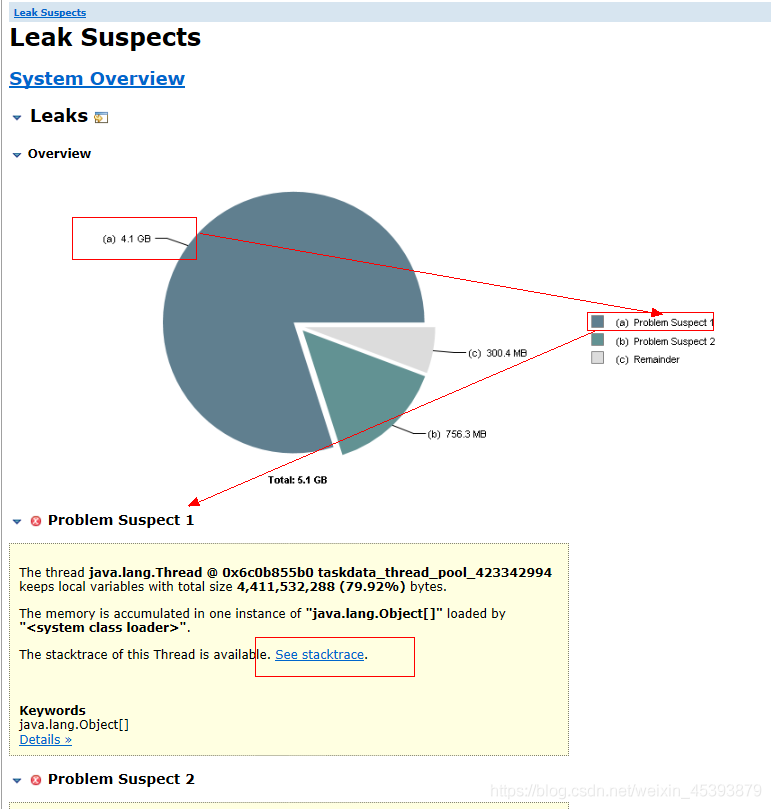
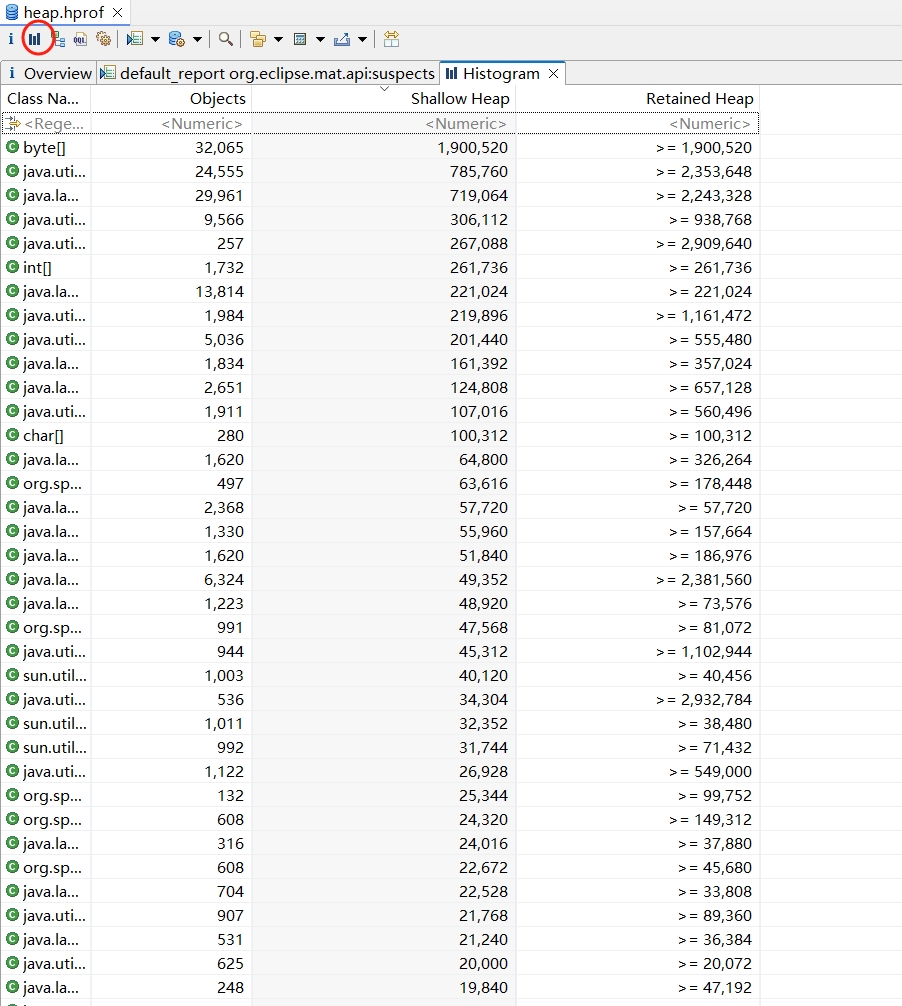
GChisto GC 日志分析工具
GCViewer GC 日志分析工具
JProfiler 商用的性能分析利器
arthas 阿里开源诊断工具
async-profiler Java应用性能分析工具,开源、火焰图、跨平台
在线分析平台GCEasy
紧急解决
重启或者下线功能,回滚版本
分析问题、重现问题:得出解决方案
java进程CPU 100%、死锁(jstack排查)
java进程内存Mem 100%?内存溢出问题?OOM有哪些异常类型?√(jstack、jmap导出dump文件后VisualVM离线分析)
jstat对比出现问题的时间点以及当前FGC的频率。监控系统监控JVM的各项指标。
频繁minor gc?因为新生代空间小导致Eden区很快填满,增大新生代空间-Xmn
频繁Full GC?
大对象:系统一次性加载了过多数据到内存中(SQL查询未分页),导致大对象进入老年代
内存泄漏:频繁创建了大量对象用完没回收(IO对象使用完后未调用close方法释放资源),程序频繁生成一些长生命周期的对象,当这些对象的存活年龄超过分代年龄时便会进入老年代,
程序BUG、程序上线、基础组件升级
代码中调用System.gc()方法
JVM参数设置问题:包括总内存大小、新生代和老年代、Eden区和S区的大小、元空间大小、垃圾回收器设置,垃圾回收算法等
Java heap space堆空间溢出,常见(对象创建太多)看是否创建了超大的对象。
java.lang.StackOverflowError栈空间溢出,栈管运行,每个方法就是一个栈帧,循环调用方法,会出现这种问题,看是否创建了超大的对象,或者产生了死循环。
Direct buffer memory 由于ByteBuffer. allocteDirect(capability)分配操作系统本地内存,不属于GC 管辖范围。不需要内存拷贝所以速度相对较快。分配太多内存不够
GC overhead limit exceeded GC连续多次GC都只回收了不到2%的极端情况下会抛出。
unable to create new native thread;多线程linux系统默认允许单个进程可以创建的线程数是1024个,应用创建超过这个数量,就会报
JDK8+永久代不会内存溢出
停顿时间长,安全点阻塞
cas处理返回时间快的,避免cpu消耗,不用转换内核态,syscnirozed内核态转换,syscnirozed死锁,relock的超时重试机制
aqs模版方法模式
设计模式使用原型模式,复制上万个对象用于消息推送,对象复杂程度,需要性能测试,浅拷贝,构造函数复杂性高时可以使用,活动、账单对象重复
工厂模式
模板方法,用户行为日志,日志格式不多,维护性好,为什么不用解释器?类膨胀,递归深度,不容易debug
适配器
观察者模式,订阅发布
提高并发量,瞬时并发量,提高单节点并发能力单接口,用资源换吞吐量,代码,异步多线程,数据库插入、索引、查询,缓存,第三方服务强依赖,多线程调用,网络带宽,尽量使用stream流,避免json
无状态容易水平拆分,引入消息队列,拆分服务,只需发送,保证接入端,加入缓存提高返回时间,使用分布式集群部署,缓存分布式部署,消息队列集群部署,数据库分布式部署和读写分离
ecache不同节点的数据同步,省市级数据,过期时间长不用同步,如果缓存redis会有额外网络开销,不变才真么存,前端缓存,时间短+redis缓存,补偿程序保证同步,可以手动或者持续监听binlog
可以放cdn,但不推荐
redis内存满了,增加redis,切片,数据分不到不同的节点上,
不能删除,不能备份,
redis压缩列表。redis列表长度小于512,且每个元素小于64字节开启压缩列表,不开启时,String,三个指针32位6-7字节,2个整数长度每个占1字节,大概占用20字节开启压缩后序列化存储,存储2个整数,一个是前一个节点的长度,和当前节点字符串的长度,调整到1024,太大的话不像,编解码性能损耗太大,代码尽量减少key,满足唯一性和可读性,代码层面对大列表存储进行数据拆分,利用分片思想在redis长列表存储结构里面,将长链表分为n个短链表。配合lua脚本,4将数据打包成二进制位。用户的位置信息,广东省广州市,在代码里面索引Map映射成01这个2个字节,能节省一半左右,性能提升:1减少快照生成时间,aof和rdb速度都快,主从同步速度加快。带宽少了,传输时间减少,从服务器加载速度加快,
高可用理解:最大限度保证服务的正常运行,保证用户服务不受到影响,需要有1合理的负载均衡,使用线程隔离,集群隔离,数据读写分离。热点数据的隔离,保护项目重点接口,2限流,舒缓请求的速度和量级
从接入层限流,分布式+lua限流,应用限流,3降级预案。超时降级、读服务降级、写服务降级,4业务代码加入重试机制,保证所有请求能别完全处理,nginx限流一般是连接数和请求数量限制,分布式+lua限流对单个用户session或者ip限流,防止单个用户恶意攻击系统或者刷流量,限制单用户的瞬间爆发量,令牌桶算法限流,应用层面对接口进行限流,分布式+lua限流不用细粒度限流为了把更多资源放在存储和查询缓存业务里面,应用限流更方便降级
手写跳表nlogn增删查
k8s中有状态与无状态服务√
| 特征 | 有状态应用 | 无状态应用 |
|---|---|---|
| 数据持久性 | 需要保存客户端状态的服务,保证数据不丢失 | 不需要~ |
| 扩展性 | 相对复杂,需要处理数据一致性问题 | 易水平扩展,只需增加副本 |
| 故障恢复 | 需要处理数据一致性问题,如数据恢复等 | 可以快速替换失败的实例 |
| 请求独立性 | 不依赖之前请求 | 依赖~,如会话数据、用户信息、数据库记录等 |
| 负载均衡 | 容易实现,没有发送请求限制 | 实例具有唯一标识(如Pod名称),客户端需要与特定的实例交互 |
| 实现过程 | 通过Deployment和Service | 通过 StatefulSet和PersistentVolume |
| Deployment控制Pod副本数和滚动更新 | StatefulSet确保每个Pod都有唯一的网络标识和持久存储 | |
| Service提供负载均衡和服务发现 | PersistentVolume提供存储支持 |
- 无状态服务:不会在本地存储持久化数据.多个服务实例对于同一个用户请求的响应结果是完全一致的.这种多服务实例之间是没有依赖关系,比如web应用,在k8s控制器 中动态启停无状态服务的pod并不会对其它的pod产生影响.
- 有状态服务:需要在本地存储持久化数据,典型的是分布式数据库的应用,分布式节点实例之间有依赖的拓扑关系.比如,主从关系. 如果K8S停止分布式集群中任 一实例pod,就可能会导致数据丢失或者集群的crash.